前言
我已经学习完了Redis的基础篇,笔记见https://blog.lecspace.com/index.php/archives/80/。但是,这只是学会使用Redis的入场券,想要在被面试官拷打redis相关知识点时游刃有余,必须要更加深入研究它。
我会跟着《Redis45讲》进行学习,这篇文章是我学习这东西的笔记。
1.怎样学Redis更好?
此节不重要,浓缩总结一下:如何学Redis?
🧭 两大维度:
- 系统维度:理解 Redis 的底层原理与架构;
- 应用维度:从实际业务场景和案例出发,掌握使用技巧。
🧩 三大主线(简称“三高”):
| 主线 | 涉及模块 | 目标 |
|---|---|---|
| 高性能 | 线程模型、数据结构、持久化、网络框架 | 提升吞吐与响应速度 |
| 高可靠 | 主从复制、哨兵机制 | 保证数据一致与高可用 |
| 高可扩展 | 数据分片、负载均衡 | 支撑大规模集群部署 |
作者建议:
- 先按“三高主线”构建知识框架;
- 再结合“应用场景驱动 + 典型案例驱动”深入学习。
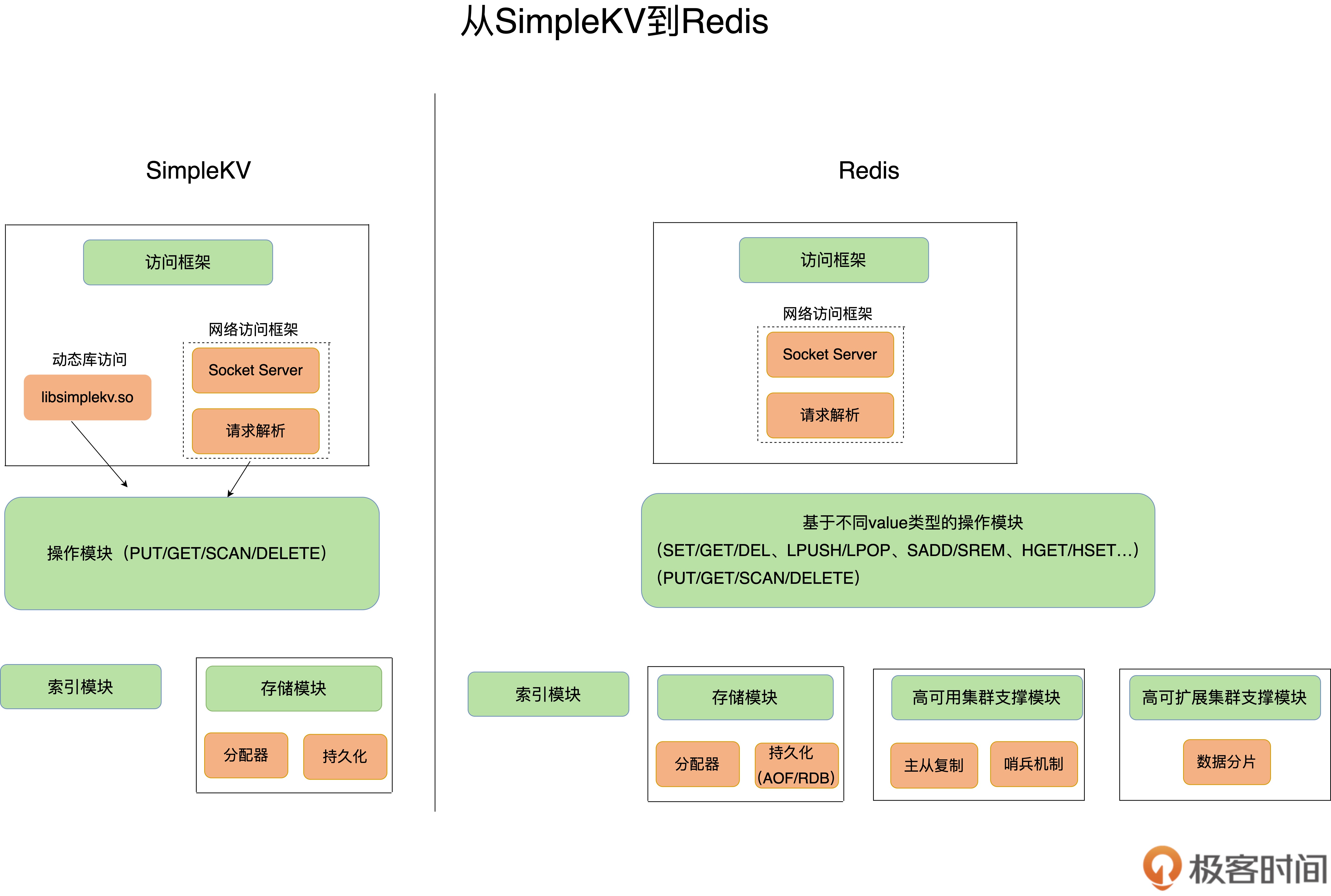
01 | 基本架构:一个键值数据库包含什么?
1)主旨
- 先用最小可用的键值库 SimpleKV 搭“骨架”,形成系统观,再带着框架去理解 Redis 的复杂特性与优化路径。
2)SimpleKV 的架构与搭建顺序
- 数据模型:Key 为
String;Value 支持基础类型(String、整数等)。
└→ 现实里的 KV(如 Redis)会把 Value 做成多类型(String/Hash/List/Set…),以适配更多场景。【重点】 - 操作接口:最小集合为 PUT/GET/DELETE/SCAN,可扩展 EXISTS。
└→ 操作能力决定适用场景:KV 易做点查/简单集合操作,但不擅长聚合计算(如平均值)。【重点】 数据放哪里:
- 内存:快,但断电丢;
- 外存:稳,但慢。
SimpleKV 选内存以贴近 Redis 的“高性能缓存”定位。【重点】
访问模式(I/O 模型):
- 库调用(如 RocksDB) vs 网络服务(如 Redis/Memcached);
- 线程/进程模型取舍:单线程易被阻塞,多线程有锁竞争。I/O 设计直接影响吞吐与延迟。【重点】
- 索引模块:按 key 找 value 的位置;内存 KV 常用 哈希表(O(1) 近似)。
└→ Redis 的多 Value 类型内部还有自己的数据结构(如列表/集合),二级结构的选择影响性能。【重点】 操作模块:
- GET/SCAN:读出 value;
- PUT:分配空间并写入;
- DELETE:删除并释放空间。
存储/持久化模块:
- 内存分配器选择会影响碎片与效率(SimpleKV 用
malloc/free,Redis 可选多种分配器); 持久化策略:
- 逐条落盘:稳但慢;
- 周期落盘:快但偶有丢失。
Redis 对持久化做了更多机制与优化(见下)。
- 内存分配器选择会影响碎片与效率(SimpleKV 用
3)从 SimpleKV → Redis 的关键“进化”
- 访问方式:以 网络服务为主(RESP 协议),通用性更强。
- 数据模型:丰富的 Value 类型 → 对应更丰富的命令(LPUSH/LPOP、SADD/SREM…)。
- 持久化:AOF(日志) + RDB(快照) 两条线,权衡性能 vs 数据安全。【重点】
- 集群/高可用:支持复制、哨兵、分片等,满足 高可靠/高扩展。【重点】
圈重点
- 系统观优先:先搭框架(数据模型→接口→I/O→索引→操作→持久化),再深入点技。
【重点:学习顺序与定位问题的方法论】 - 操作能力决定边界:KV 擅长点查与简单集合操作,不擅长复杂聚合(平均值、join)。
【重点:选型与场景匹配】 - 多类型 Value = 性能与空间的权衡:每种结构背后都有不同的时间/空间复杂度与内存布局。
【重点:命令性能差异的根源在“底层数据结构”】 - I/O 与线程模型是吞吐/延迟的第一性问题:单线程避免锁但怕阻塞;多线程并发高但有竞争。
【重点:理解 Redis 为何“单线程也高性能”及其边界】 - 内存分配与碎片会放大延迟波动与内存占用。
【重点:生产环境经常被忽视的性能坑】 持久化两条线(AOF/RDB):
- AOF:更安全,可控刷盘,可能带来写放大/延迟抖动;
- RDB:整库快照,恢复快但快照时有资源压力。
【重点:按业务容忍度选择或组合】
- 从 SimpleKV 到 Redis 的“加法”:网络协议、丰富数据结构、两种持久化、复制/哨兵/分片。
【重点:Redis 的价值不只在快,更在“完备的工程化能力”】
速用清单
- 说清 KV 的能与不能:点查强,聚合弱。
- 题到 性能:先问 I/O/线程模型、数据结构、内存分配、持久化策略。
- 题到 持久化:AOF vs RDB 的权衡与组合策略(如 AOF everysec + 定期 RDB)。
- 题到 集群/高可用:复制、哨兵、分片的一句话职责与常见坑(复制延迟、重分片、热点键)。
- 题到 命令效率:回到底层结构(Hash/Skiplist/Ziplist/Quicklist/Dict…)解释“为什么”。
SimpleKV 相比 Redis 还缺什么?
- 协议与客户端生态(RESP、Pipeline、批量、连接管理)。
- 过期与淘汰策略(TTL、LRU/LFU、定期/惰性删除)。【重点】
- 复制/哨兵/分片(高可用与水平扩展)。【重点】
- 更丰富的数据结构(Hash/List/Set/ZSet、Stream、Bitmap/HyperLogLog、Geo)。
- 持久化完善(AOF 重写、RDB 触发策略、混合持久化、恢复流程)。【重点】
- 内存治理(分配器选择、碎片率监控、maxmemory 策略)。
- 可观测性(慢日志、命令统计、热点 Key、延迟监控)。
- 安全与多租户(权限/ACL、隔离/限流/防穿透)。
- 脚本与事务(Lua、事务/原子性原语、分布式锁语义)。
02 | 数据结构:快速的Redis有哪些慢操作?
1)Redis 为啥快?
- 内存数据库:操作发生在内存,先天快。
- 数据结构选得好:键值组织 + 值的底层结构共同决定了增删改查的复杂度。【重点】
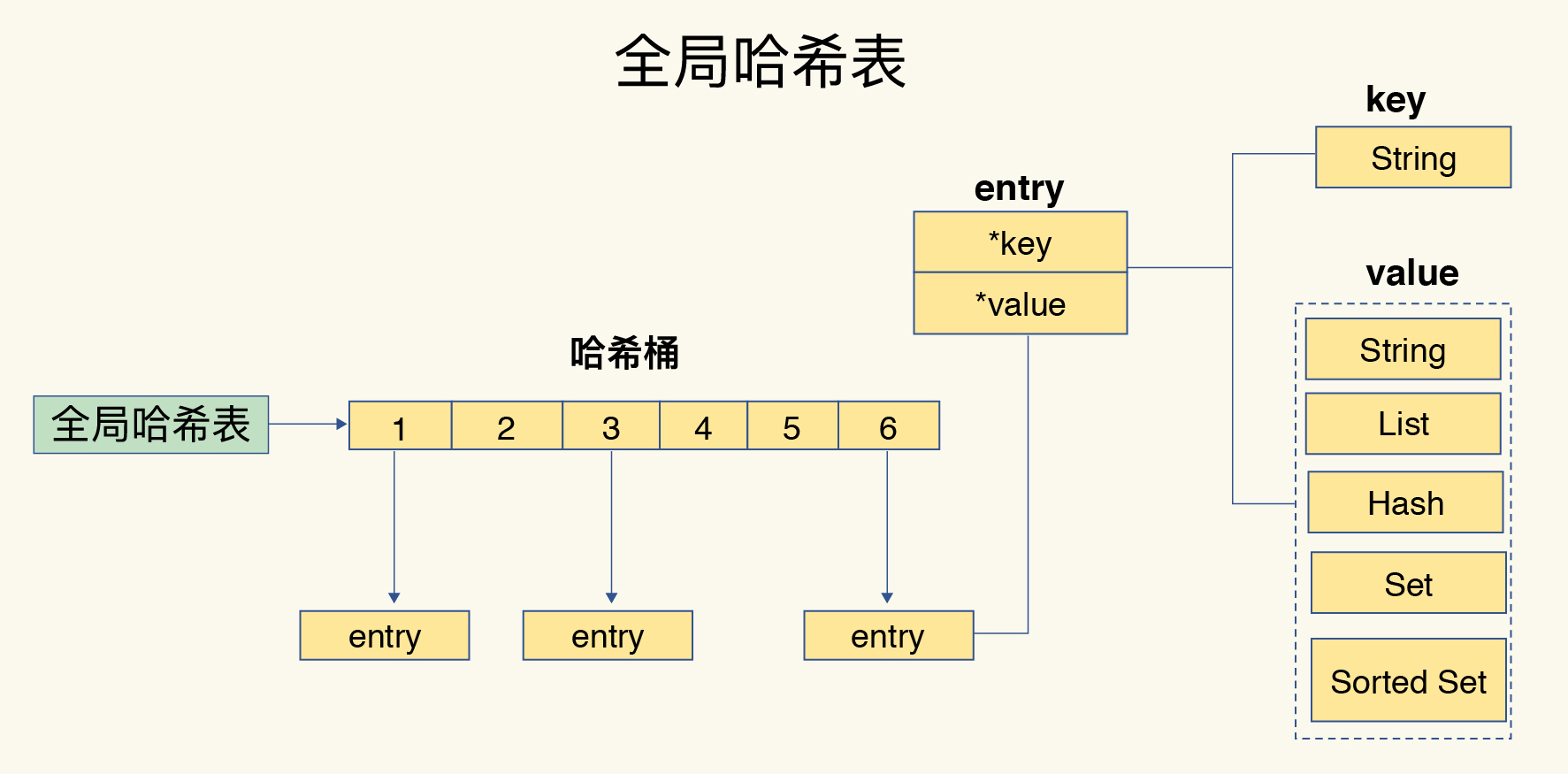
2)键和值如何组织?
全局哈希表(dict)保存所有键值对:
- 哈希桶数组 → 每个桶存 entry(含
key*和value*指针)。 - 查找复杂度 ≈ O(1)(与数据量弱相关)。【重点】
- 哈希桶数组 → 每个桶存 entry(含
- 冲突处理:链式哈希(同桶元素用链表串起来)。
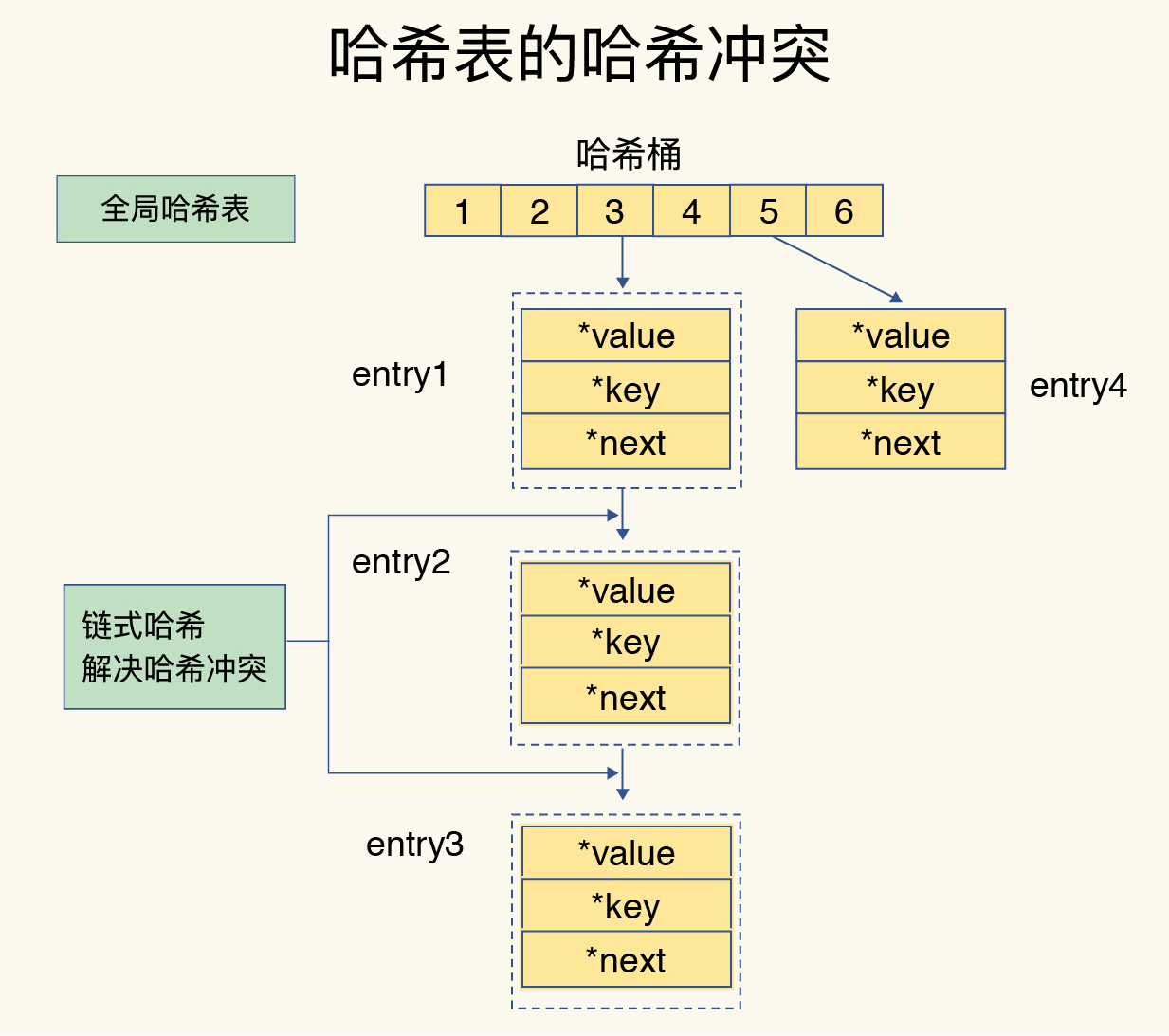
- 扩容机制:渐进式 rehash(请求期间分批搬迁哈希桶,避免一次性阻塞)。【重点】
3)值(集合类型)的底层数据结构(6 选)
- String:SDS(简单动态字符串)。
List / Hash / Set / ZSet:会在两种结构间切换(按大小/编码等阈值):
- 整数数组(intset)、双向链表(linkedlist)、压缩列表(ziplist)、哈希表(hashtable)、跳表(skiplist)。【重点】
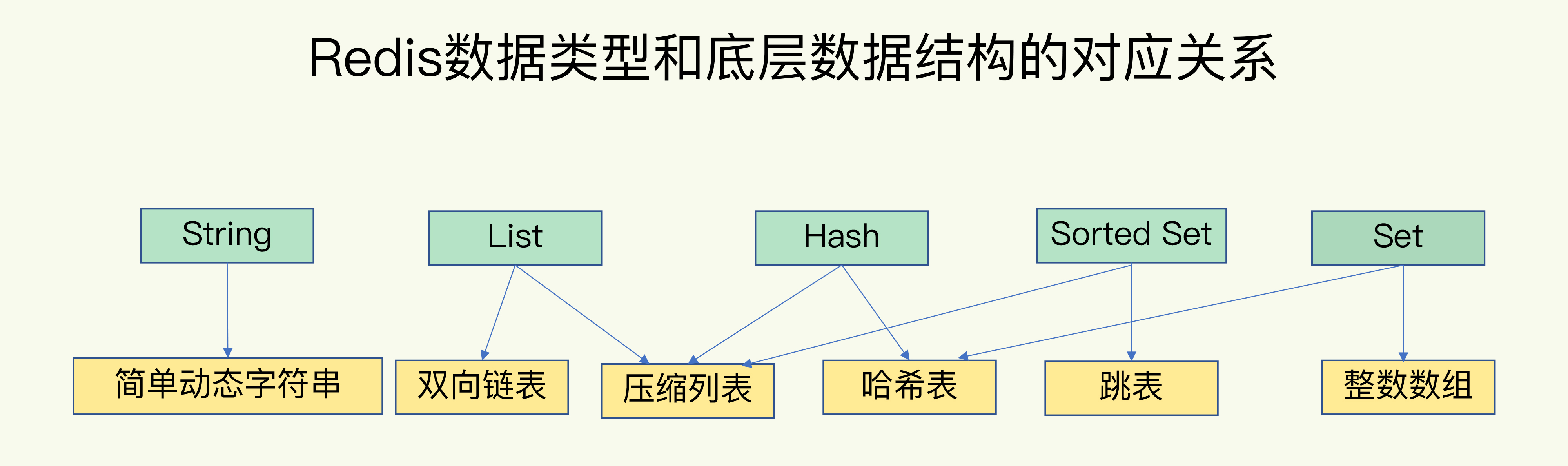
直觉复杂度梯度(查找):
- hashtable:O(1);skiplist:O(logN);
- linkedlist / ziplist / intset:O(N)(顺序访问为主)。

4)集合操作的复杂度——四句口诀
- 单元素操作是基础:底层若是哈希表,多为 O(1)(如 HGET/HSET、SADD/SREM)。【重点】
- 范围操作非常耗时:遍历/范围读取多为 O(N)(如 HGETALL、SMEMBERS、LRANGE、ZRANGE)。【重点】
- 统计操作通常高效:记录了长度/基数的结构,LLEN/SCARD 常为 O(1)。
- 例外情况有几个:List 的 头尾操作(LPUSH/RPUSH/LPOP/RPOP)可 O(1)(有偏移量/指针可直达)。
5)慢从哪来?
- 哈希冲突链过长;
- 一次性 rehash 会阻塞(Redis 用渐进式缓解);【重点】
- 对集合做全量遍历/范围操作导致 O(N);
- 选择了不合适的底层结构(如把 List 当随机读写容器)。
实战“避坑清单”(按影响度排序)
- 避免 O(N) 的范围命令:HGETALL / SMEMBERS / LRANGE / ZRANGE 等,
→ 尽量用 SCAN/HSCAN/SSCAN/ZSCAN 渐进遍历;限制返回条数。【重点】 - 单元素优先:HGET/HSET、SADD/SREM、ZADD/ZREM 等是基础操作路径,延迟稳定。
- 别把 List 当数组:List 适合 队列(头尾),不适合随机访问/大范围读取。
→ 队列/日志:LPUSH/RPOP 等;随机访问考虑 Hash/Sorted Set。 关注哈希表负载与 rehash:
- 大批量写入可能触发扩容;
- 服务繁忙期避免集中触发;
- 合理批量/预热/均衡写入节奏。【重点】
按“规模/类型”选编码:
- 小而简单的集合:ziplist/intset(省内存、CPU 缓存友好);
- 变大后自动“升级”为 hashtable/skiplist(更快)。【重点】
你最该记的“圈重点”
- 全局哈希表 + 渐进式 rehash 是 Redis 查找快且不抖的根基。【重点】
- 集合底层结构两套切换(空间 vs 时间):小集合偏紧凑结构(ziplist/intset),大集合自动升级(hashtable/skiplist)。【重点】
- 范围 = O(N),生产环境要警惕;用 SCAN 系列替代全量遍历。【重点】
- List 的价值在“头尾 O(1)”,主要用于队列,不做随机读。【重点】
- 复杂度=数据结构:先判断底层结构,再推操作成本,少靠死记硬背。【重点】
面试/答辩速背(30 秒)
- Redis 快:内存 + 数据结构。键值由全局哈希表组织,冲突用链式,渐进式 rehash摊薄扩容成本。
- 集合类型底层:hashtable O(1)、skiplist O(logN)、其余多为 O(N)。
- 命令策略:单元素优先,范围慎用 → 用 SCAN;List 只做队列头尾。
- 小集合走 ziplist/intset 省内存,变大自动升级到更高效结构。
“每课一问”参考思路
问:整数数组(intset)和压缩列表(ziplist)查找不是 O(N),为啥还用作底层?
答:因为它们在小集合下有显著工程优势:
- 内存开销小(紧凑、额外指针少);
- CPU 缓存友好(连续内存,遍历快);
- 编码简单、分配/拷贝便宜(小集在 O(N) 的常数项很小);
- 按阈值“自动升级”到 hashtable/skiplist,兼顾小集合省内存与大集合高性能。【重点:小规模走空间效率,大规模走时间效率】
03 | 高性能IO模型:为什么单线程Redis能那么快?
一句话总览(背诵版)
- Redis“单线程”只指:网络 I/O + KV 读写在一个线程;持久化/异步删除/集群同步等有额外线程。
- 用单线程的核心原因:避免多线程对共享数据的并发控制与锁开销。
- 快的本质:内存操作 + 高效数据结构(哈希表、跳表)+ I/O 多路复用(select/epoll 等)+ 非阻塞套接字 + 事件回调。
- 关键阻塞点被规避:
accept()、recv()改为非阻塞,由内核监听 FD,事件就绪再回调处理。
面试常问点 & 标准作答要点
1) Redis 真的是单线程吗?
- 答:对外部服务路径(网络 I/O 与键值读写)是单线程;后台任务(持久化、异步删除、集群数据同步)有额外线程。
- 加分:单线程减少锁竞争、上下文切换、并发 Bug;更易维护和调试。
2) 为什么不做多线程?
- 多线程需要保护共享资源(如 List 的长度计数),必须串行化关键区或加锁 → 锁竞争、上下文切换、复杂性↑,吞吐不一定随线程数线性增长,甚至下降。
3) 单线程为何还能很快?
- 内存级操作 + 高效数据结构(哈希表/跳表)
- I/O 多路复用:内核同时监听多个监听/已连接套接字(FD),请求就绪触发事件 → 事件队列 → 单线程回调处理。
- 非阻塞 Socket:避免阻塞在
accept()/recv();Redis 线程可继续处理其他事件。 - 事件驱动:避免忙轮询,减少 CPU 浪费,提升吞吐和响应。
4) I/O 多路复用怎么落地?
- 机制:select / epoll(Linux)、kqueue(FreeBSD)、evport(Solaris)。
- 流程:设置 FD 非阻塞 → 注册到多路复用器 → 内核监听 → 事件触发 → 放入事件队列 → 回调处理函数(如
accept/readhandler)。

5) Redis 的潜在阻塞点/慢点(面试高频追问)
- 网络层:
accept()、recv()(已用非阻塞+多路复用规避)。 - 慢命令/高复杂度命令:
SORT、SUNION、ZUNIONSTORE、KEYS、超大LRANGE/HGETALL等。 - 大 Key/Big Value:单线程处理一个大对象会拉长事件处理时间。
- 持久化:RDB/AOF 重写期间的 I/O 压力、写放大。
- 内存复制/序列化:协议编解码、大量返回值拷贝。
- 网络带宽/内核参数:大批量返回、Nagle、缓冲区设置不当等。
- 阻塞式操作:同步删除、脚本执行时间过长、事务中重命令。
- 集群/复制:全量同步、慢网络导致的复制积压。
和 Go 后端的关联点(容易被问)
- Go 的多路复用模型:Go 的
netpoller在 Linux 下基于 epoll;与 Redis 的事件驱动理念一致(就绪再处理)。 - 避免在 Redis 上做重活:在 Go 层限制慢命令、避免大 Key、细化数据结构(分片/拆桶)、限流与超时。
- 连接管理:用连接池(如
go-redis),Pipeline/批量以减少 RTT;合理ReadTimeout/WriteTimeout。 - 观测与保护:慢查询日志、
latency doctor、maxmemory策略、AOF 后台重写时的降压策略。 - 脚本与事务:Lua 脚本控制原子性但要短小;事务避免长队列。
图景化理解(面试口述示意)
单线程事件环:
- 内核监听一组 FD(监听 + 已连接)。
- 事件就绪 → 投递到事件队列。
- Redis 单线程按事件处理(
accept/read/ 解析 / 执行命令 /send)。
- 关键点:单线程不在某个 FD 上阻塞,把等待交给内核,自己只做“就绪即处理”。
你可以这样回答“为什么 Redis 单线程还这么快?”
Redis 的对外服务路径是单线程,避免了多线程对共享数据结构的加锁与上下文切换开销;它把等待交给内核,通过 非阻塞 socket + epoll/kqueue 的多路复用 实现事件驱动,单线程就能高并发处理大量连接。同时,Redis 基于内存与高效数据结构(哈希表/跳表)把单次操作成本压到极低,所以整体吞吐非常高。
面试加分扩展:Redis 6.0 的多线程
- 要点:Redis 6.0 在 I/O 阶段(读写/解析/回复)引入多线程以进一步利用多核,核心命令执行仍保持单线程逻辑,避免数据结构并发控制复杂化。
- 如何衔接本章:多路复用 + 事件环依旧存在,多线程更多用于I/O offload,不破坏核心串行语义。
复习清单(打星必背)
- “单线程”的准确含义与后台线程存在
- 单线程优点:无锁/少锁、上下文切换少、可维护性好
- 非阻塞 socket 与 阻塞点:
accept/recv - select/epoll/kqueue 的就绪事件驱动模型
- Redis 高性能三件套:内存 + 高效数据结构 + I/O 多路复用
- 面试陷阱:慢命令、大 Key、持久化冲击、复制放大
- Go 侧优化:Pipeline/批量、连接池、限时限流、慢日志与告警
- Redis 6.0 多线程的I/O 加速与执行仍单线程的设计取舍
“每课一问”参考答案(潜在瓶颈)
- 协议解析/序列化成本
- 单条命令执行过久(慢命令/大返回集)致事件环停顿
- 持久化/复制期间的磁盘与网络压力
- 大 Key/热 Key导致单事件占用时间过长
- 网络栈/带宽与内核参数(缓冲区、队列)限制
04 | AOF日志:宕机了,Redis如何避免数据丢失?
一、AOF 的作用与场景
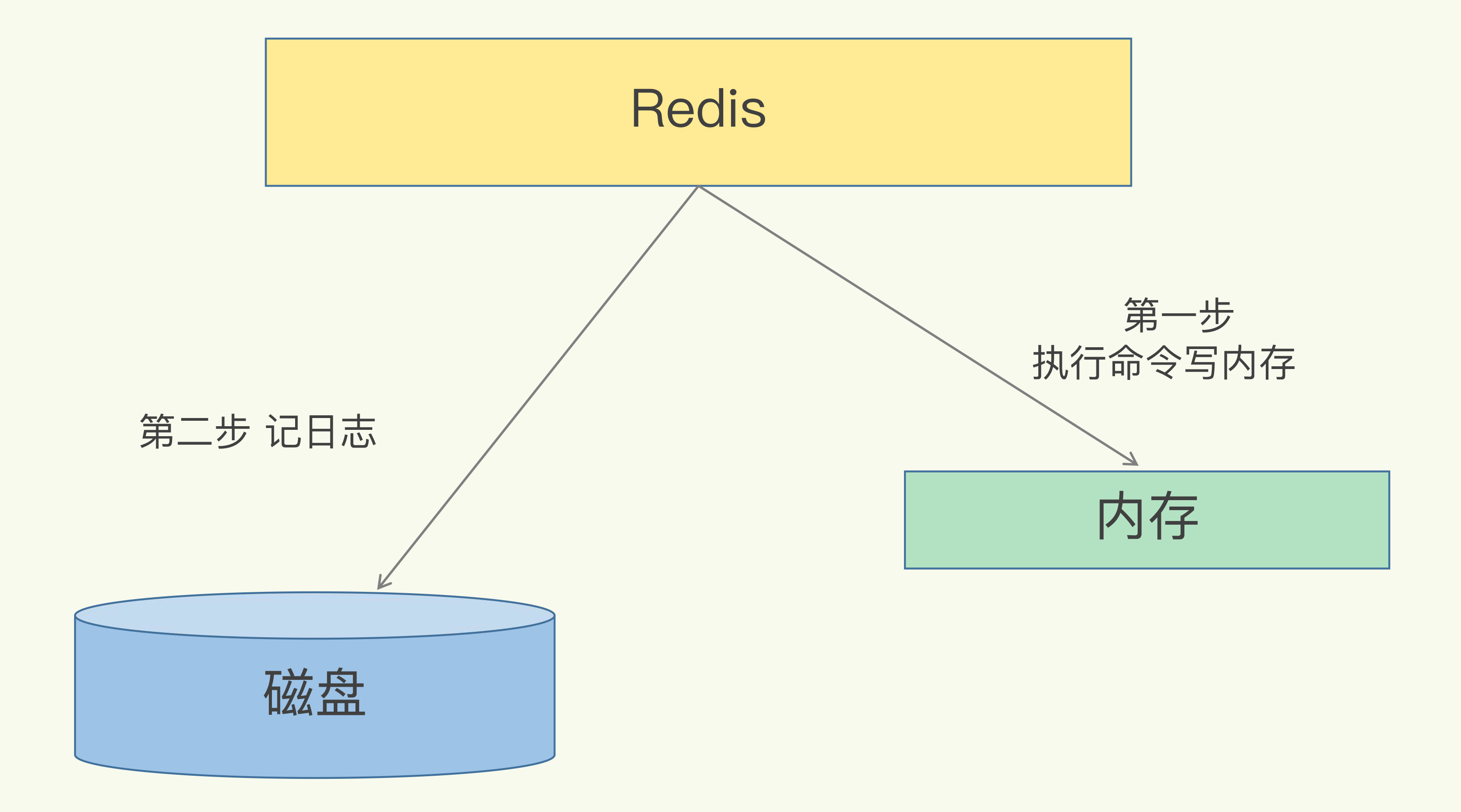
🔹 Redis 为什么需要持久化?
- Redis 通常运行在内存中,宕机会导致数据丢失。
从数据库恢复数据:
- ❌ 频繁访问数据库 → 数据库压力大
- ❌ 恢复慢 → 响应变慢
- ✅ 持久化的目标:在不依赖外部数据库的情况下,保证数据可靠性。
🔹 Redis 持久化方式
- AOF 日志(Append Only File)
- RDB 快照(下一节)
二、AOF 的核心机制
1️⃣ AOF 是“写后日志”
- 数据库的 WAL(Write Ahead Log)是写前日志:先写日志再更新。
Redis 的 AOF 是写后日志:
先执行命令(更新内存) → 再记录日志(命令文本)
📘 为什么写后?
- 如果先记日志再执行,可能会把错误命令写入日志,导致恢复出错。
- 写后日志只记录执行成功的命令,保证日志的正确性。
优点:
- ✅ 只记录合法命令
- ✅ 不阻塞当前命令执行
风险:
- ⚠️ 刚执行完命令但未写入日志 → 宕机会丢失该命令
- ⚠️ 写日志慢(磁盘 I/O 压力大)→ 阻塞后续命令
三、AOF 三种写回策略(appendfsync)
| 策略 | 写回时机 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|---|
| always | 每条命令执行完后立刻写盘 | 几乎不丢数据 | 性能最差,主线程阻塞明显 | 数据绝对不能丢(金融类) |
| everysec | 每秒异步写盘 | 性能好,影响可控 | 宕机可能丢最近 1 秒数据 | 性能与可靠性折中(默认) |
| no | 操作系统决定 | 性能最高 | 宕机丢数据风险最大 | 数据可从 DB 重建的缓存场景 |
📌 核心考点:
Redis 的三种持久化策略体现了系统设计的经典哲学——trade-off(性能 vs. 可靠性)。
四、AOF 文件过大的问题与解决方案
问题:
- 文件系统对文件大小有限制。
- 文件越大,追加命令越慢。
- 宕机恢复时需重放所有命令,恢复速度变慢。
✅ 解决方案:AOF 重写机制(Rewrite)
⚙️ 原理:
- 根据当前内存中的最新数据生成新的 AOF 文件
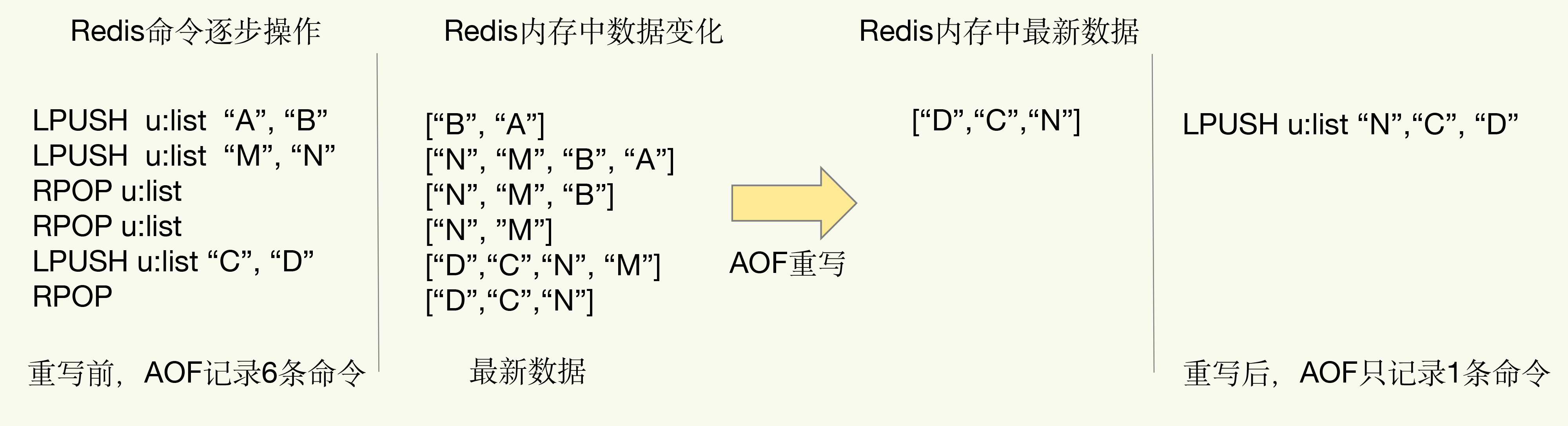
- 不再保存所有历史命令,而是只记录恢复当前状态所需的最简命令集合。
📘 举例:
- 原日志中 6 条命令修改一个 list,最终状态是
[D, C, N] 重写后只保留:
LPUSH u:list "N" "C" "D"- 多条操作 → 一条命令(多变一)
📈 优点:
- 文件显著变小
- 重放更快
五、AOF 重写的实现细节(重点)
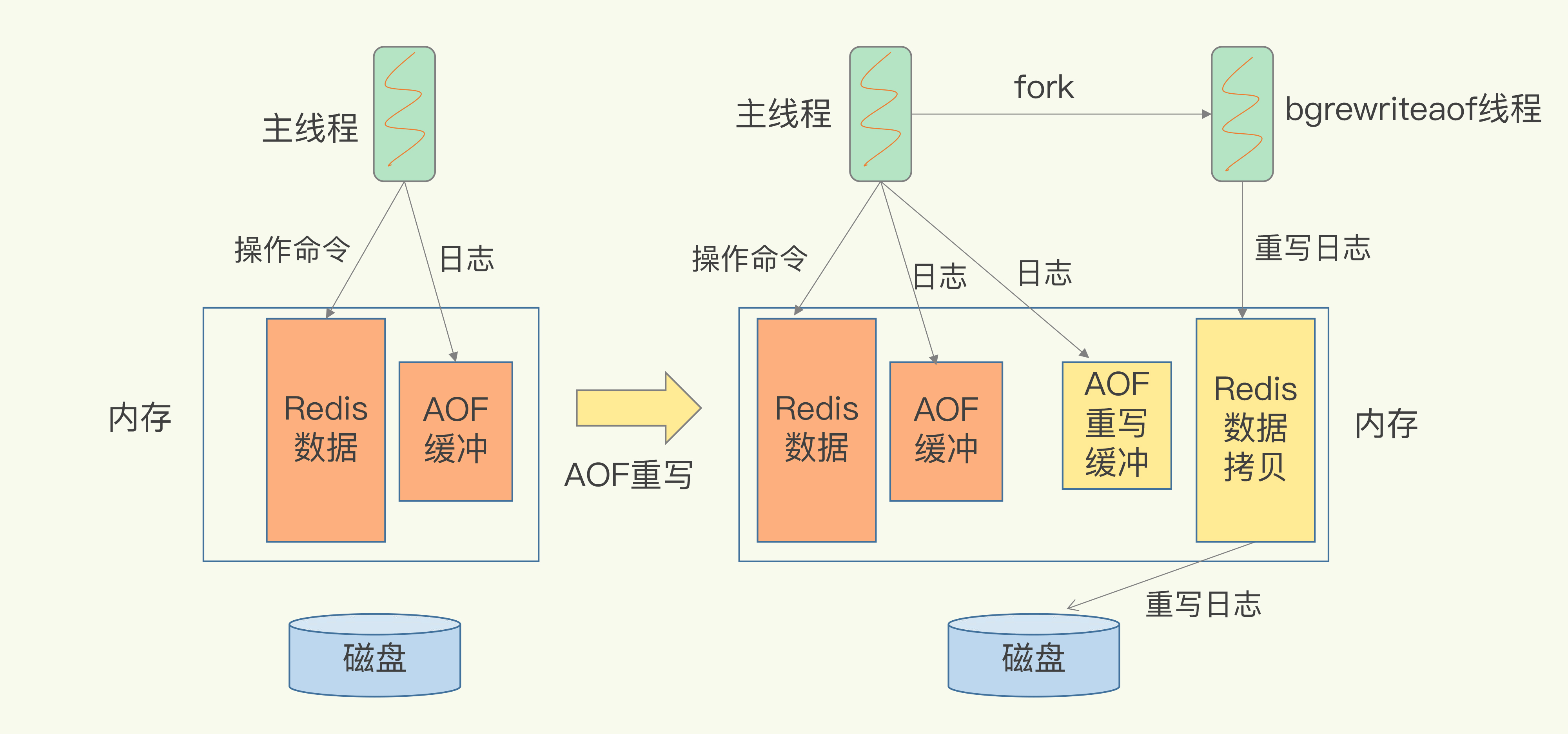
🔹 非阻塞的重写过程
主线程执行
bgrewriteaof命令后:- fork 一个子进程(bgrewriteaof)
- 子进程拷贝主线程的内存快照,用于生成新的 AOF 文件
- 主线程继续处理客户端请求,不被阻塞
🔹 “一个拷贝,两处日志”
- 一个拷贝:
fork 时复制主线程的内存,用于子进程重写。 两处日志:
- 主线程继续记录当前命令到旧 AOF 文件缓冲区
- 同时把新命令也写入重写缓冲区
- 重写完成后,把重写缓冲区的命令追加到新文件,替换旧文件。
📌 结论:
AOF 重写通过子进程完成,不阻塞主线程,但 fork 阶段会有短暂的内存复制耗时(可能造成瞬时阻塞)。
六、潜在风险与面试延伸题
⚠️ 1) AOF 重写会完全无阻塞吗?
不会。虽然重写由子进程执行,但 fork 期间会执行写时复制(Copy-On-Write),如果 Redis 数据量大,fork 时间会显著变长,可能短暂阻塞主线程。
⚠️ 2) 为什么重写日志不直接共用原 AOF 文件?
防止数据不一致:
- 重写过程和主线程的写操作是并行的。
- 共用同一文件可能导致新旧命令交织,日志错乱。
- 所以采用独立重写文件,最后再整体替换。
七、面试口述范式(推荐复述模板)
Redis 的 AOF 是一种写后日志机制,会记录执行成功的命令,用于宕机恢复。
它提供三种写回策略:always、everysec、no,在性能与可靠性之间做权衡。
为了防止 AOF 文件过大,Redis 支持后台非阻塞重写,由子进程bgrewriteaof完成,通过“一个拷贝,两处日志”保证数据不丢。
这体现了 Redis 在持久化机制中对性能、可靠性和主线程无阻塞的综合平衡。
八、Go 后端开发面试关联点
Go 服务常用
go-redis,要了解:- AOF 配置 (
appendfsync everysec) - RDB/AOF 混合持久化策略
- AOF 配置 (
设计缓存时:
- 明确 缓存数据是否要求持久化
- 合理选择策略:缓存型用
no,持久化用everysec
监控与优化:
- 关注
aof_current_size、aof_base_size - fork 时间过长 → 调整
vm.overcommit_memory
- 关注
若问“Redis 为什么快还能持久化?”:
- 持久化异步化 + fork + COW + 写后日志 → 主线程性能不受影响
九、复习要点清单 ✅
- Redis 持久化的两种方式:AOF / RDB
- AOF 是写后日志,记录执行成功的命令文本
- 三种写回策略:Always / Everysec / No
- AOF 文件过大 → AOF 重写机制
- 重写通过
bgrewriteaof子进程执行 → 非阻塞主线程 - “一个拷贝,两处日志”机制
- 潜在阻塞点:fork 过程(COW)
- 不共用日志的原因:避免数据交错/不一致
- trade-off 思想:性能与可靠性的取舍
05 | 内存快照:宕机后,Redis如何实现快速恢复?
一、RDB 是什么?解决了 AOF 的什么痛点
- 定义:把某一时刻内存中的所有数据写到磁盘(RDB 文件 = Redis DataBase snapshot)。
- 对比 AOF:AOF 恢复要重放命令,日志多时恢复慢;RDB 直接读入内存,恢复快。
二、核心设计与关键问题
1) “给哪些数据拍照?”
- 全量快照:把所有键值写入 RDB(“大合影”)。文件越大,写盘时间越久。
2) “拍照时能不能动?”
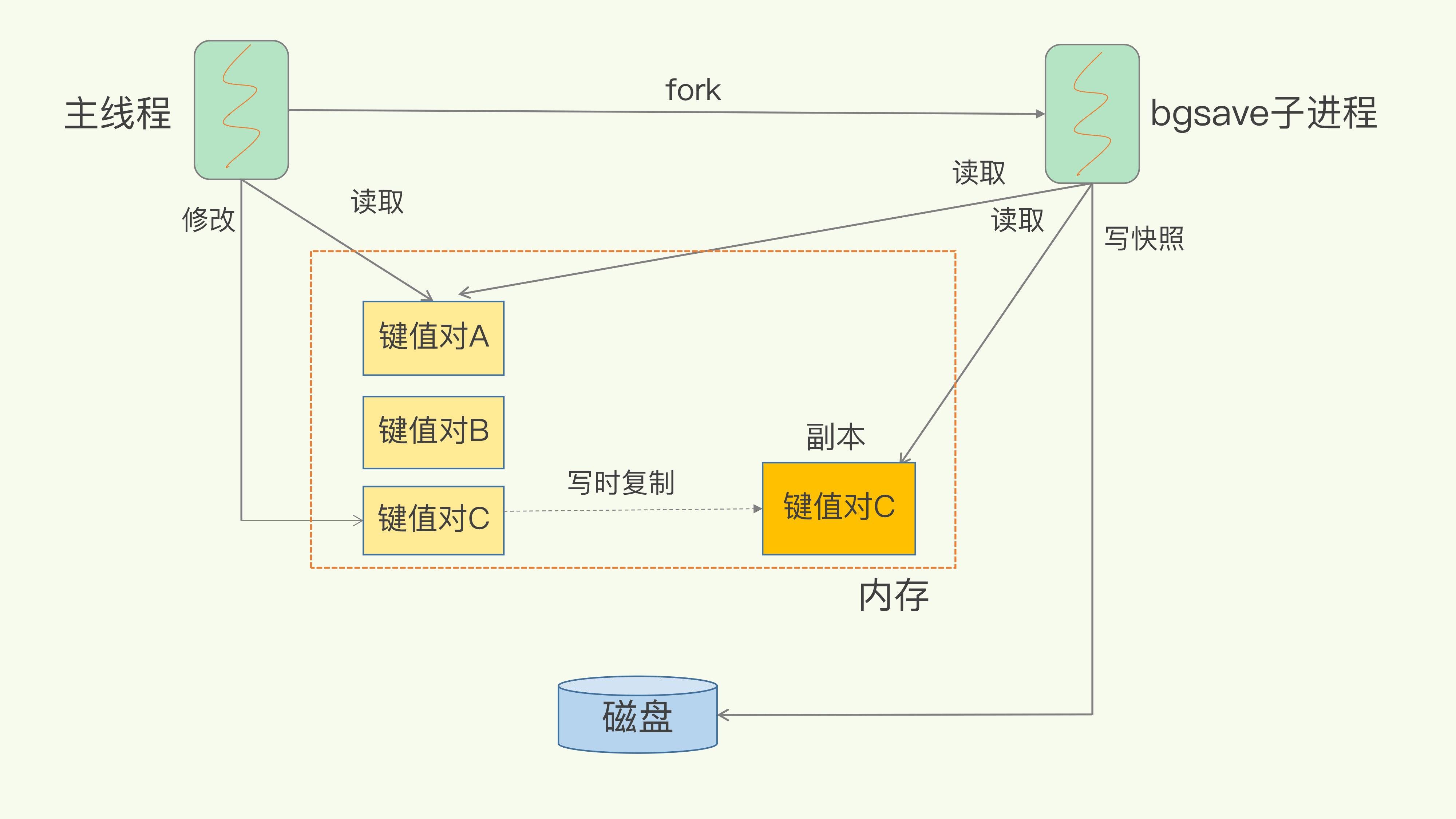
- bgsave(推荐,默认):主线程
fork子进程写 RDB,主线程不被长期阻塞。 - save:主线程直接写 RDB,会阻塞。
- COW(写时复制):bgsave 期间有写请求,修改的页被复制一份;子进程写旧快照页,主线程继续改新页 → 快照完整 + 业务可写。
面试金句:RDB = bgsave + COW,既保证快照一致性,也不拖慢写路径。
三、快照频率的取舍(不能“每秒连拍”)
- 频繁全量快照的两大代价:
① 磁盘带宽被吃满(前一次未完,下一次又来)
② fork 本身阻塞主线程(内存越大越久) - 过稀又有数据丢失风险(两次快照间的修改不在 RDB 内)。

四、增量思路 & 混合持久化(RDB + AOF)
- 增量快照理念:只记录自上次快照以来被修改的数据,但需要额外“修改元数据”,空间与复杂度↑。

Redis 4.0 混合方案(强烈推荐):
- 周期性 RDB(提供快速恢复)
- 两次 RDB 之间用 AOF 记录变更(减少 RDB 频率 & AOF 体量、避免频繁重写)
- 做到恢复快、丢失少、开销可控。

五、面试高频问答范式
Q:RDB 会阻塞吗?
A:save 会;bgsave 主逻辑不阻塞,但fork 短时阻塞不可避免。写入阶段依赖 COW,主线程可继续写。
Q:为什么不用“每秒 bgsave”?
A:磁盘压力+频繁 fork 造成性能抖动与主线程短阻塞,得不偿失。
Q:如何既恢复快又尽量少丢?
A:RDB + AOF(everysec)混合持久化:RDB 负责基线,AOF 覆盖快照间变更。
六、Go 后端落地建议(易被追问)
- 持久化策略:生产建议 RDB + AOF(everysec)。
- 运维调度:在低峰期做 RDB;写高峰期避免触发快照。
- 监控项:fork 时长、磁盘带宽、
used_memory与 COW 额外内存、RDB 用时。 内核/配置:
vm.overcommit_memory=1(降低大内存 fork 失败几率)rdb-save-incremental-fsync yes(增量 fsync 降低大抖动)- SSD、充足可用内存,避免 COW 导致 OOM。
七、选择建议(背诵版)
- 不能丢:RDB + AOF 混合。
- 可分钟级丢失:仅 RDB。
- 只用 AOF:优先 everysec(性能/可靠性折中)。
每课一问 · 场景风险分析(面试思路)
条件:2C/4GB/500GB 云主机;Redis 占 2GB;写 80%;持久化仅 RDB。
主要风险
- fork 短时阻塞:2GB 内存 + 高写入 → fork 更慢,主线程短暂停顿(尾延迟抖动)。
- COW 额外内存:写 80% 导致大量页被改写,COW 复制页激增,瞬时内存需求可能逼近/超过 4GB → OOM 风险或内核杀进程。
- 磁盘 I/O 压力:全量 RDB 写盘时间长;与常态写放在同一盘上会争用带宽,放大延迟。
- 数据丢失窗口:仅 RDB → 两次快照间宕机会丢最近窗口内的数据,写多更敏感。
- CPU 资源紧张:2C 下,fork+压缩+IO 校验等占用 CPU,影响请求处理。
改进建议
- 启用 RDB + AOF(everysec) 混合;降低 RDB 频次、在低峰执行。
- 使用 SSD,并确保与业务日志/其他重 IO 任务分盘。
- 预留足够内存(≥ 数据 + 峰值 COW 余量),或限制写峰值。
- 调整内核与 Redis:
vm.overcommit_memory=1、rdb-save-incremental-fsync yes。 - 观察 fork 时间、RSS、页脏化速率、磁盘吞吐;必要时分片/集群降低单实例内存规模。
复习清单(打星记忆)
- RDB = 快照文件,恢复快;AOF = 命令日志,恢复慢但粒度细
- bgsave + COW 核心机制;
save会阻塞 - 频繁全量快照不可取:磁盘 & fork 抖动
- 混合持久化(RDB + AOF everysec) = 恢复快 + 丢失少 + 开销可控
- 高写入场景仅 RDB 的五大风险与缓解措施
06 | 数据同步:主从库如何实现数据一致?
一、为什么需要主从复制?
目标:
提高可靠性
- 数据尽量少丢失(RDB / AOF 负责)
- 服务尽量少中断(主从复制负责)
提升读性能
- 读写分离:主库负责写,从库负责读
核心机制:
👉 Redis 通过 主从模式(Master-Slave) 实现数据冗余与服务高可用。
- 写:只能在主库执行
- 读:主、从均可
- 同步:主库负责把数据变化同步给从库

二、主从复制的核心流程(第一次全量同步)
主从复制的首次同步分为 三阶段:
🔹 1. 建立连接与协商(准备阶段)
- 从库执行:
replicaof <master_ip> <port> - 从库发送
psync ? -1 主库响应
FULLRESYNC <runID> <offset>runID:主库唯一标识offset:复制偏移量
👉 此阶段确定:是否为首次全量复制 + 主从同步起点。
🔹 2. 全量复制(数据传输阶段)
- 主库执行
bgsave生成 RDB 文件。 - 从库清空自身数据,加载主库发来的 RDB 文件。
- 同时主库将新收到的写操作缓存进 replication buffer。
🔹 3. 增量同步(追数据阶段)
- 主库发送
replication buffer中的新增写命令给从库。 - 从库执行这些命令,实现主从一致。

📌 面试常问:
为什么主从复制用 RDB 不用 AOF?
答:
RDB 文件更适合一次性全量传输(体积小、加载快),而 AOF 文件冗长且重放慢。
三、级联复制(主-从-从)
问题:
主库同时对多个从库做全量复制 →
会导致主库 CPU 负载高、fork 阻塞、网络带宽压力大。
解决:主-从-从 模式(级联复制)
- 让部分从库从另一个从库复制数据。
- 主库只需同步给第一级从库。
👉 减轻主库压力、提高复制性能。
命令示例:
replicaof <上级从库IP> 6379
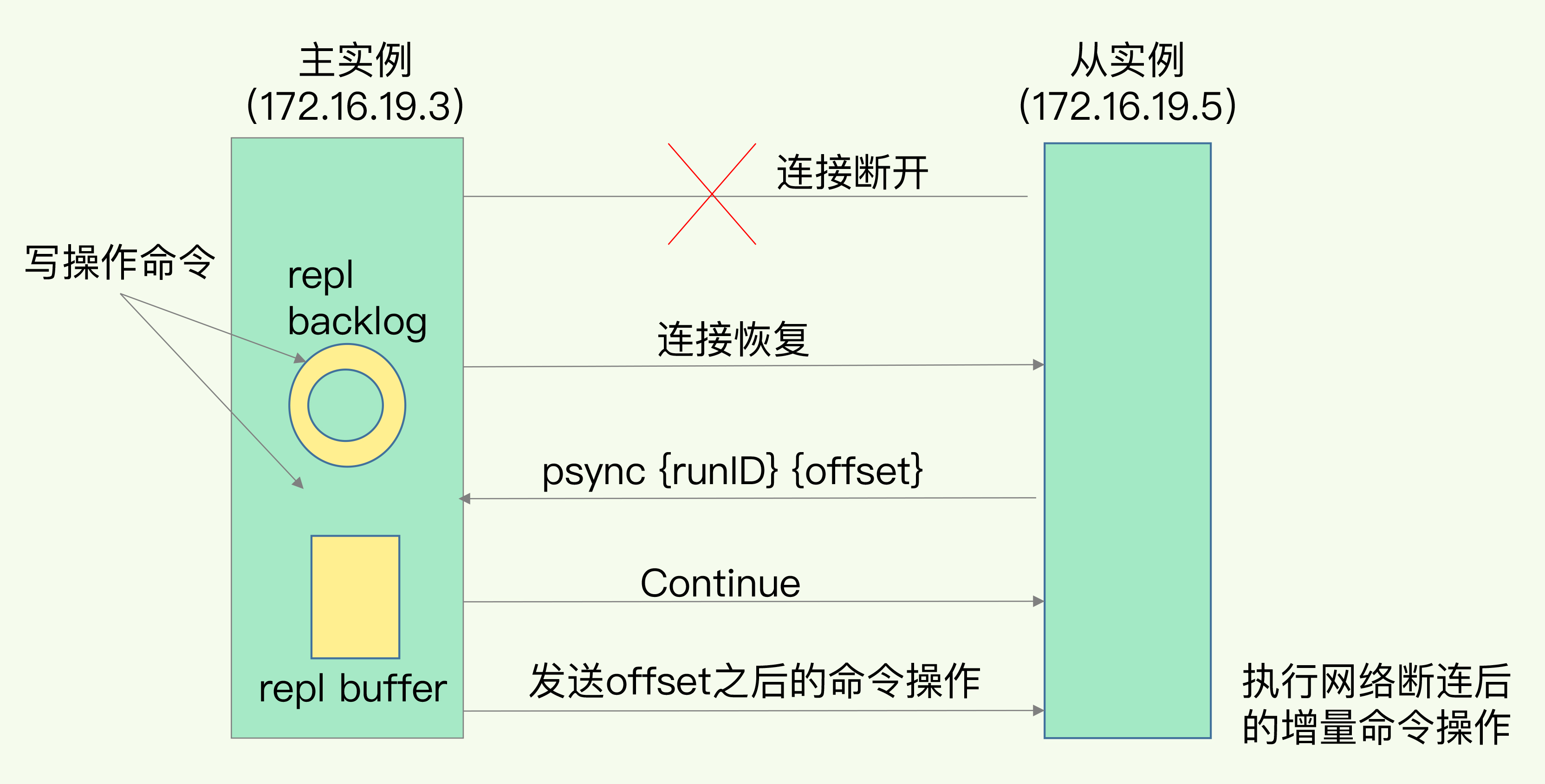
四、长连接命令传播阶段
- 主从完成全量同步后,保持长连接,
- 主库实时将写命令传播到从库。
- 避免频繁建立连接的性能损耗。
风险: 网络断连。
- 若断连,主从库无法同步,数据会产生延迟或不一致。
五、网络断连后的同步机制(增量复制)
Redis 2.8 之后引入 增量复制(Partial Resync),避免频繁全量复制。
📍 核心机制:repl_backlog_buffer
- 主库维护一个 环形缓冲区,记录命令历史。
主从分别维护偏移量:
master_repl_offsetslave_repl_offset
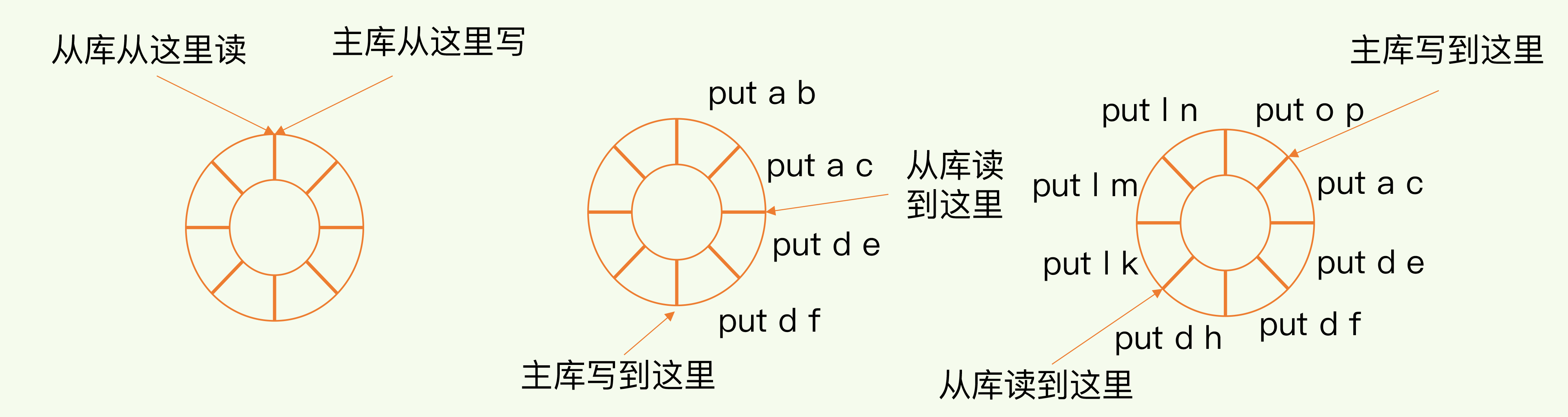
断连后,从库上报自己的 offset,
- 若数据仍在缓冲区中 → 增量复制;
- 若数据被覆盖 → 重新全量复制。
缓冲区大小配置:
repl_backlog_size = (主库写入速率 - 传输速率) × 操作大小 × 2👉 一般设为估算值的 2~4 倍,防止覆盖丢数据。
六、面试重点总结(必背)
| 考点 | 要点 |
|---|---|
| 主从复制作用 | 高可用 + 读写分离 |
| 同步模式 | 全量复制、命令传播、增量复制 |
| 全量复制阶段 | 建立连接 → 传 RDB → 传 buffer |
| 增量复制机制 | 利用 repl_backlog_buffer 追补缺失命令 |
| RDB vs AOF | RDB体积小传输快;AOF太大不适合复制 |
| 主-从-从 | 分担主库压力,优化复制性能 |
| 网络断连处理 | 断后通过 offset 差值进行增量同步 |
| 参数调优 | repl_backlog_size、避免过小导致回退全量复制 |
| 面试陷阱题 | 为什么不用 AOF?增量复制怎么避免数据不一致? |
✅ 面试回答模板示例
Redis 通过主从复制实现高可用与读写分离。
第一次同步采用全量复制(RDB 文件 + 缓冲命令),之后通过长连接持续命令传播。
若网络中断,2.8 之后支持增量复制,通过 repl_backlog_buffer 保存主库命令历史,仅同步差异部分。
为避免缓冲覆盖,应调大 repl_backlog_size。
若主库压力过大,可使用主-从-从级联复制结构
07 | 哨兵机制:主库挂了,如何不间断服务?
1️⃣ 背景与目标
主从模式痛点:主库一旦故障
- 从库无法继续复制 → 数据演进停滞
- 写请求无人可接 → 服务中断
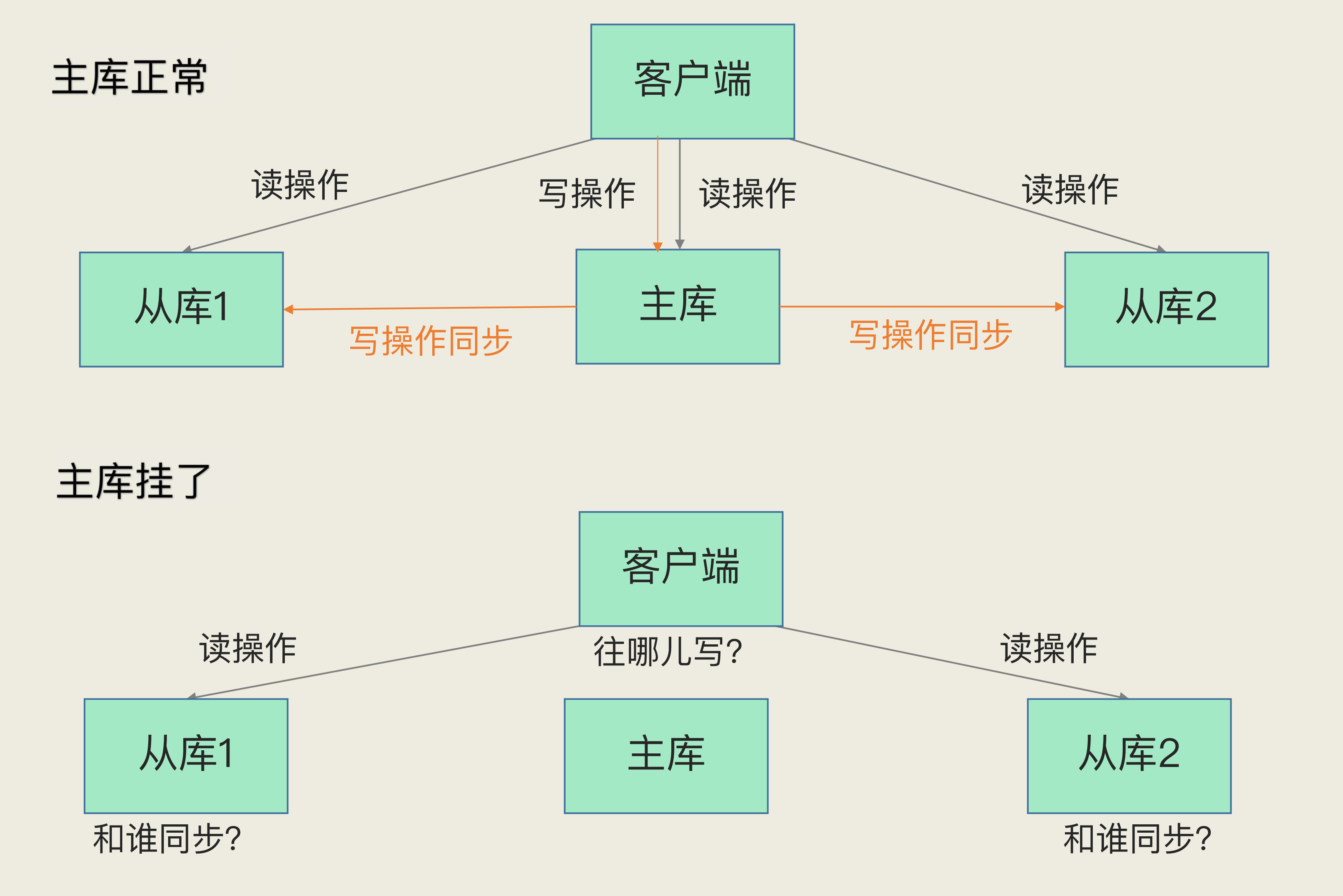
哨兵的作用:在主库故障时自动完成主从切换,尽量做到服务无感恢复
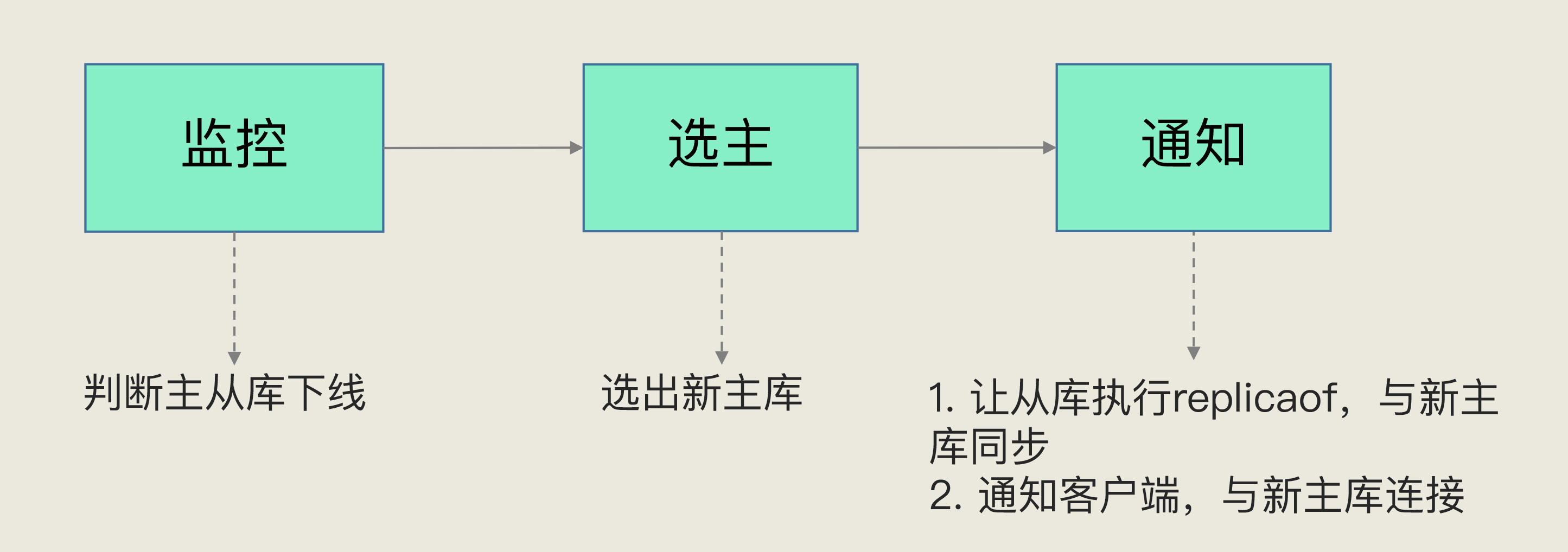
- 三大任务:监控、选主、通知
2️⃣ 三大任务(流程总览)
监控(PING 心跳)
- 定期对主/从库发送 PING,判定存活状态
选主(Failover 决策)
- 主库确定下线后,在从库中筛选并确定新主库
通知(拓扑切换)
- 通知其他从库:
replicaof <new-master> <port> - 通知客户端:将请求重定向到新主库
- 通知其他从库:
面试关键词:故障转移(Failover) = 主观下线 → 客观下线 → 选主 → 通知
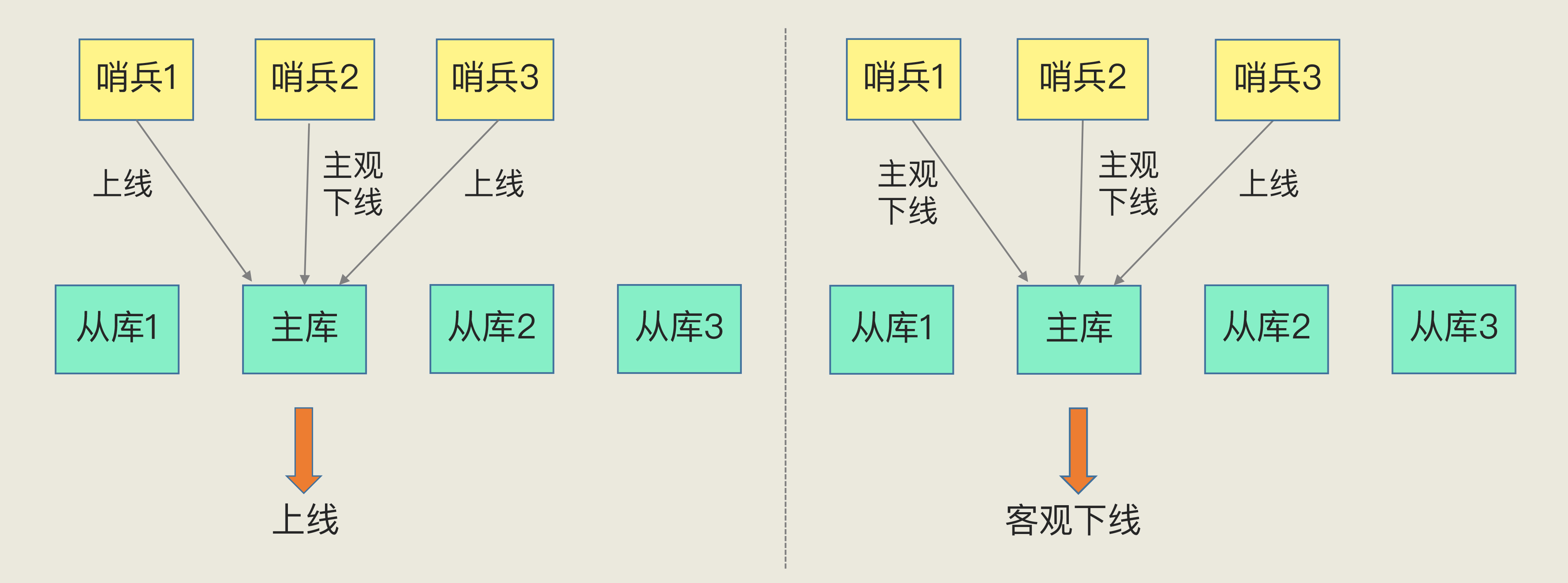
3️⃣ 下线判定:主观下线 vs 客观下线(必考)
- 主观下线:单个哨兵基于 PING 超时,先认为某实例下线
- 客观下线:多哨兵“少数服从多数”投票通过(一般需要 ≥ N/2+1)后,确认主库下线并触发切换
- 意义:降低误判(网络拥塞/瞬时抖动引起的假故障)
记忆点:主观是个人看法,客观是群体共识;主库切换只在“客观下线”后触发。
4️⃣ 选主逻辑:筛选 + 打分(高频细节)
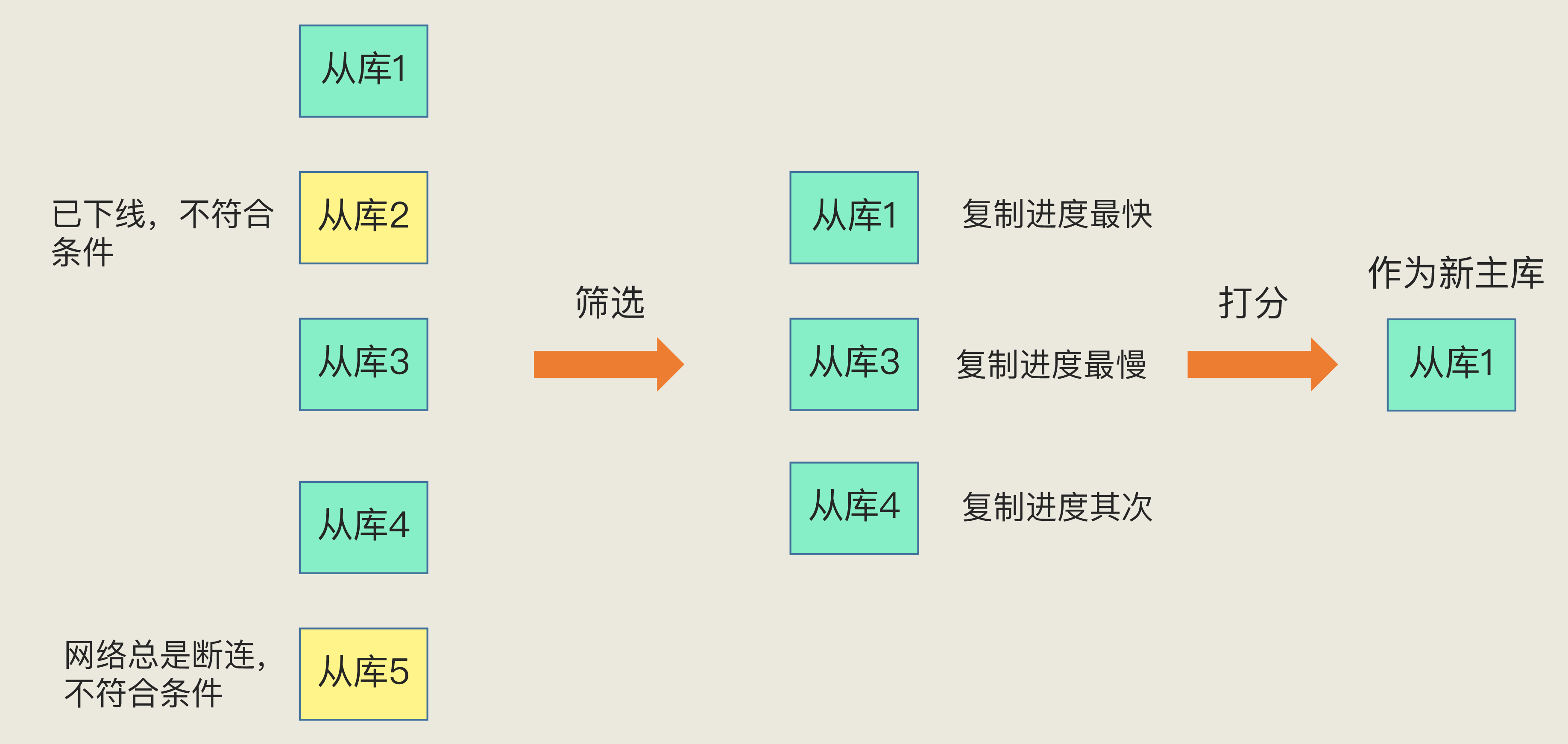
A. 先筛选
- 要求从库在线,且历史网络稳定
参考配置:
down-after-milliseconds定义连接最大超时- 若一定时间窗口内断连次数过多(文中示例:>10 次),判为不稳定 → 淘汰
B. 再打分(逐轮决胜)
- 从库优先级(
slave-priority/replica-priority)高者胜 复制进度接近主库者胜
- 主库:
master_repl_offset - 从库:
slave_repl_offset - 越接近,数据越新 → 分数越高
- 主库:
- 实例 ID 较小者胜(作为最终平手裁决)
面试常见追问:为什么看 offset?*因为最接近主库的从库,切上去*数据最新、回放成本最小。
5️⃣ 通知与收敛
- 从库统一改向新主库复制(
replicaof) - 客户端获知新主库地址,将写请求切至新主库(读也可跟随策略切换)
6️⃣ 典型面试问答(直接背)
Q1:为什么要“主观下线/客观下线”两级判定?
A:单哨兵易受自身网络/负载影响产生误判。多哨兵投票形成“客观下线”可显著降低误切换。
Q2:选新主库的具体规则?
A:“筛选 + 三轮打分”:
在线且网络稳定 → 优先级高 → 复制进度更接近主库 → ID 小者胜。
Q3:主库宕机到新主库就位期间,客户端能否正常请求?需要做啥?
A:切换存在短暂不可用窗口。为尽量无感:
- 使用哨兵感知的客户端(能从哨兵拉取新主库信息)
- 客户端增加重试/重连策略与超时合理配置
- 写请求在切换完成后自动落到新主库
Q4:如何降低误判与抖动?
A:部署多个哨兵(常见 3 或 5 个)、合理设置 down-after-milliseconds,并确保哨兵与数据节点的网络质量。
7️⃣ 易错与优化点(面试加分)
- 误判代价大:错误切主会引入多轮数据同步与拓扑切换 → 需依赖多数派判定
- 筛选维度别只看“当前在线”:要结合历史断连频次
- 客户端不能“被动等待”:应具备哨兵发现与自动重连能力
- 读写分离场景:切主期间可暂将只读流量打到从库,写流量等待新主就位
- 配套监控:关注心跳延迟、投票决策时间、切换总时长、复制延迟等指标
8️⃣ 复盘清单(考前 30 秒过目表)
- 主从与高可用的区别(数据可靠 vs 服务不中断)
- 哨兵三任务:监控 / 选主 / 通知
- 主观下线与客观下线区别与投票阈值
- 选主流程:筛选(稳定性)→ 优先级 → 复制进度 → ID
- 切换窗口内客户端应对:哨兵感知 + 重试/重连
- 关键参数:
down-after-milliseconds、(优先级)slave-priority - 为什么要多哨兵、常见部署数(3/5)
08 | 哨兵集群:哨兵挂了,主从库还能切换吗?
1️⃣ 目标与价值
- 主从自动切换在哨兵单点失效下仍可继续:降低误判、保障故障转移(Failover)可执行性。
- 哨兵集群承担三件事:监控 → 选主 → 通知(从库与客户端)。
2️⃣ 哨兵如何“组成集群”与“发现节点”
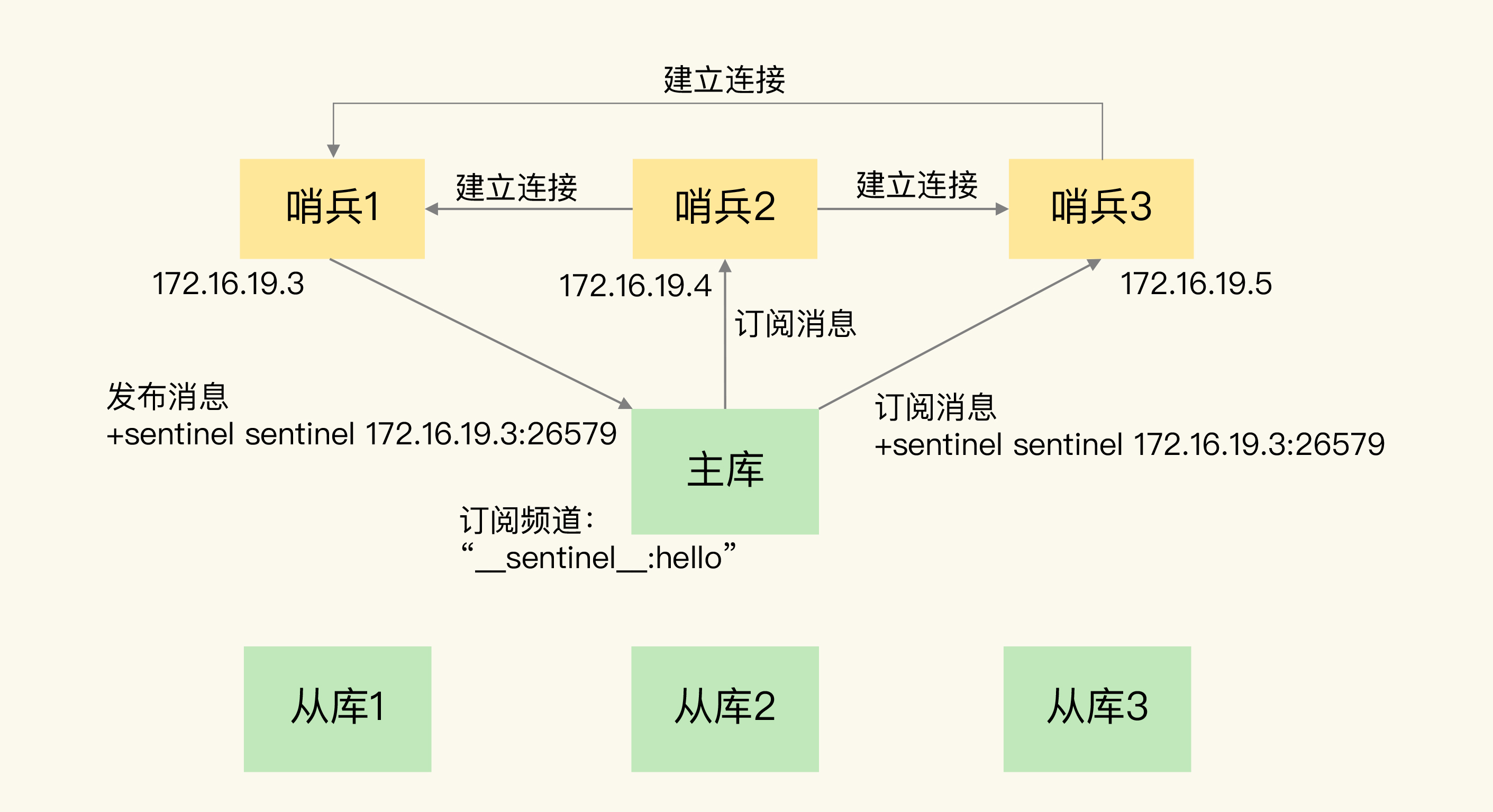
A. 哨兵之间的发现:pub/sub(频道:sentinel:hello)
任一哨兵连接主库后:
- 发布自身地址到
sentinel:hello - 订阅该频道,获得其他哨兵地址
- 发布自身地址到
- 据此互连,形成哨兵集群,后续用于状态协商/投票。
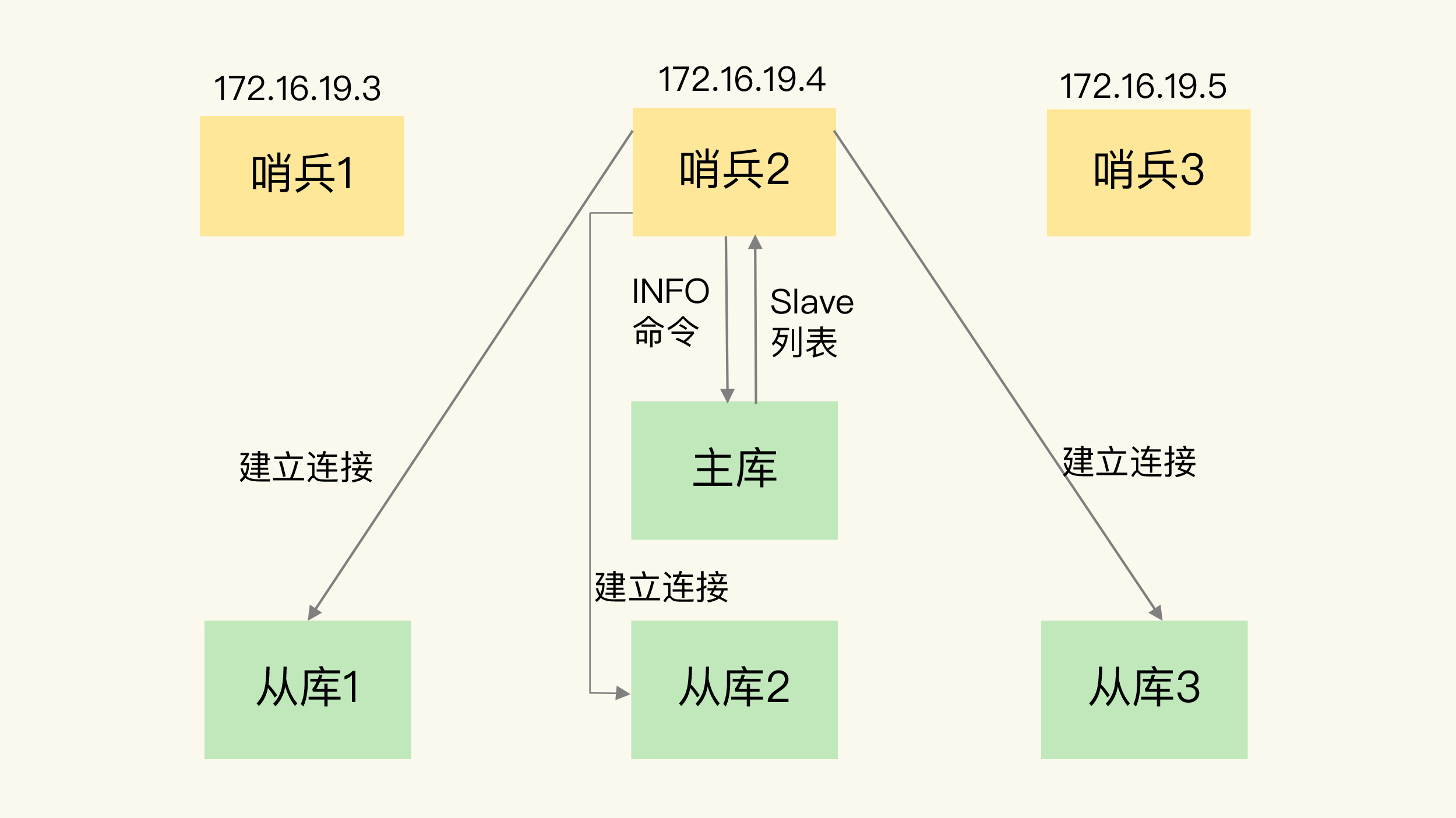
B. 发现从库:INFO
- 哨兵向主库发
INFO,拿到从库清单(IP/Port),逐个建立连接以做心跳监控与后续重定向。
C. 通知客户端:哨兵自身的 pub/sub 事件
客户端可订阅哨兵事件频道(如:
+odown、switch-master等):+odown: 实例进入客观下线switch-master: 产生新主库(含 IP/Port),客户端据此重连
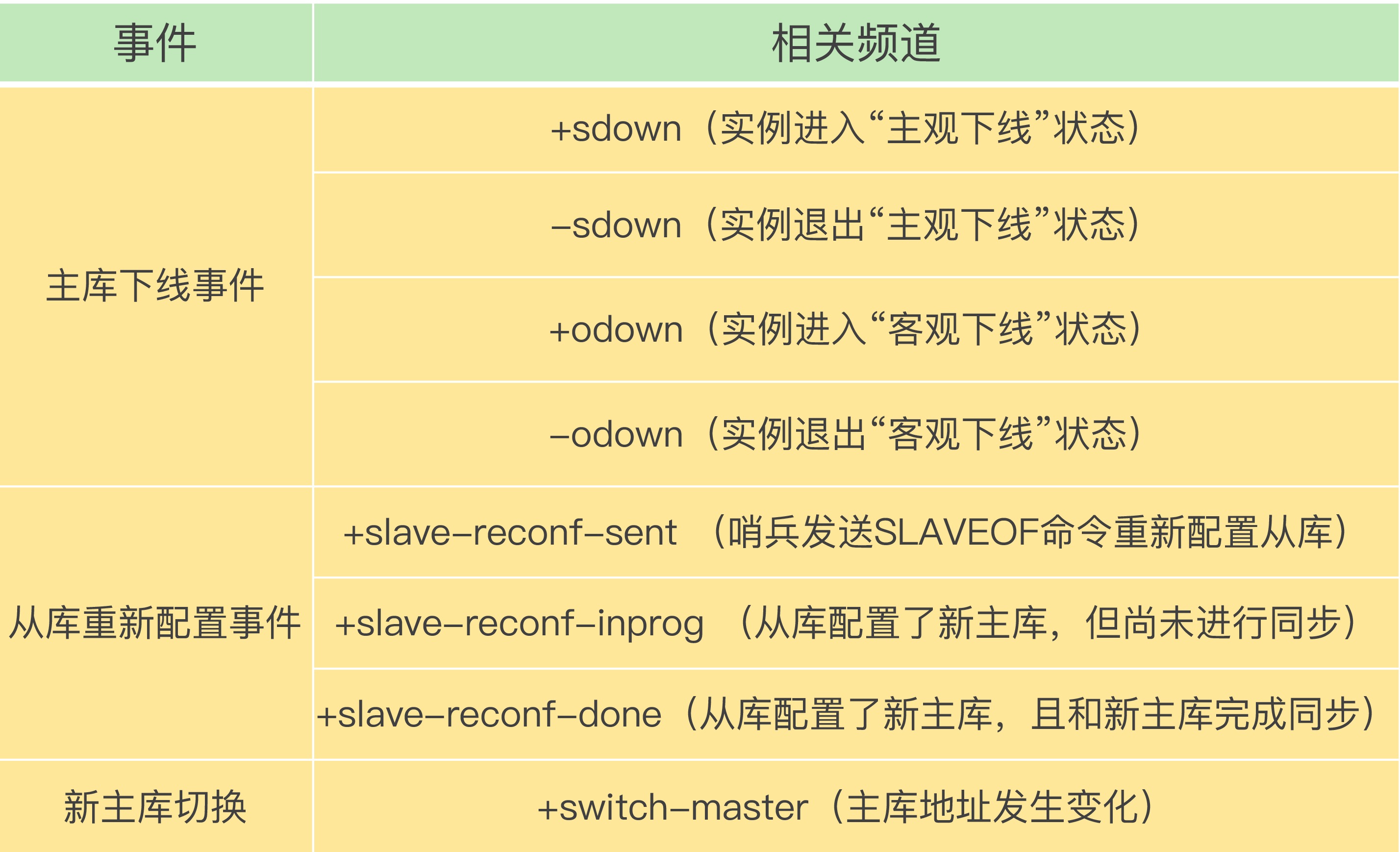
面试关键句:哨兵-哨兵靠sentinel:hello互发现;哨兵-从库靠INFO;哨兵-客户端靠哨兵自身pub/sub事件。
3️⃣ 下线判定:主观下线 & 客观下线(必考)
- 主观下线(SDown):单个哨兵基于 PING 超时的本地判断。
- 客观下线(ODown):多哨兵“少数服从多数”(投票达到 quorum)后形成共识 → 才触发切主流程。
记忆:个人感觉(SDown)≠ 集体共识(ODown);切换只在 ODown 后进行。
4️⃣ 谁来执行切换:Leader 选举(仲裁)
- 任一哨兵判断主库 SDown → 发
is-master-down-by-addr收集票数; - 拿到 quorum 票后,可标记 ODown;
随后发起 Leader 选举(谁来真正做切换):
需满足:
- 半数以上赞成(> N/2)
- 且 ≥ quorum
- 失败则等待一段时间(故障转移超时的 2 倍)再选,防止拥塞期抖动。
实战要点:至少 3 个哨兵,2 个很脆弱(任一宕机即无法达成多数)。
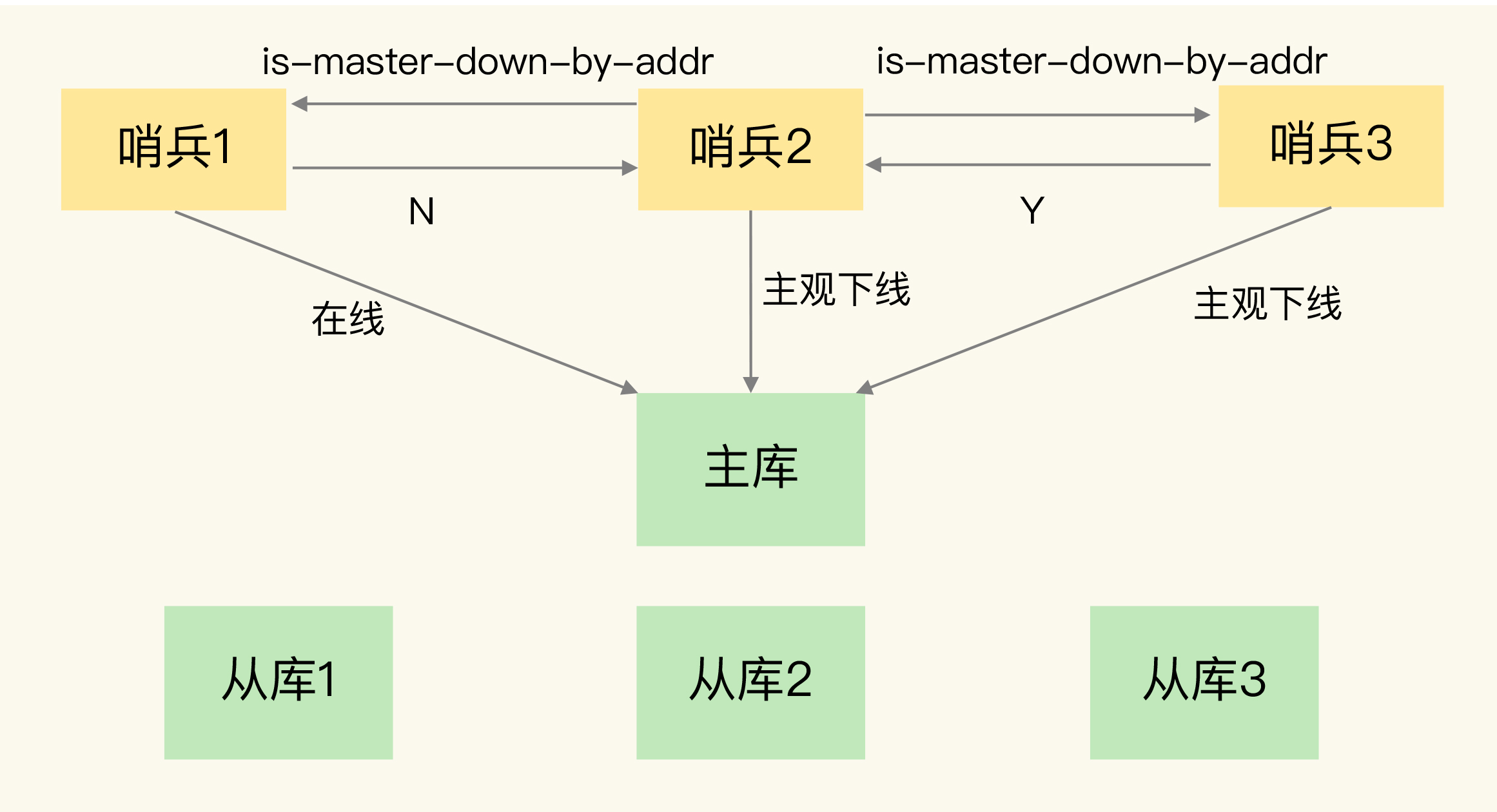
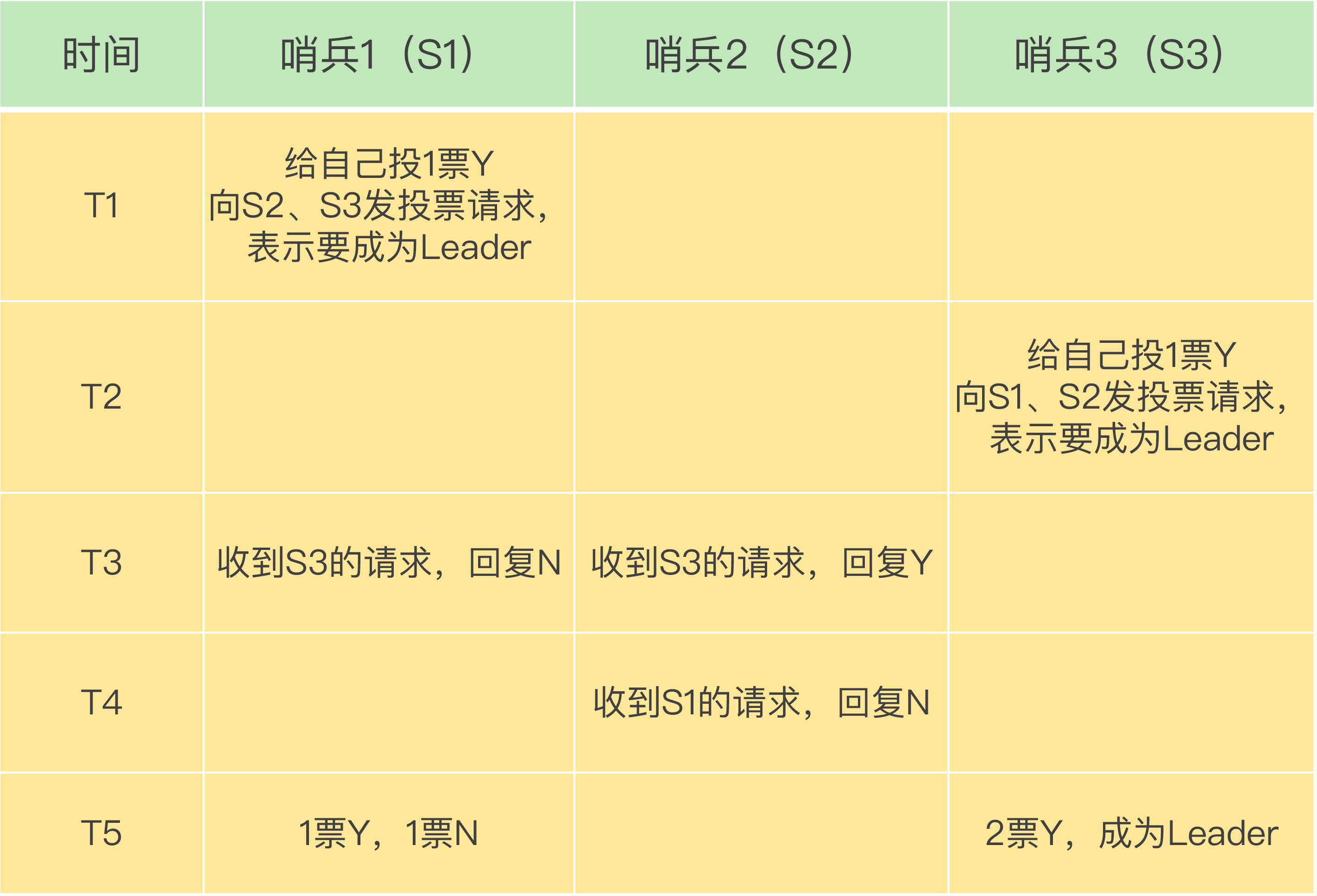
5️⃣ 选主后的收敛(通知)
Leader 哨兵:
- 通知其他从库:
replicaof <new-master> <port> - 向客户端发布
switch-master事件(携带新主库地址)
- 通知其他从库:
- 客户端需实现哨兵发现与自动重连/重试,缩短不可用窗口。
6️⃣ 关键配置 & 实战坑位
sentinel monitor <master-name> <ip> <port> <quorum>:最小化配置即可形成集群(其余通过互发现)。- 配置一致性极重要:尤其
down-after-milliseconds(主观下线阈值)需在所有哨兵上保持一致,否则难以形成 ODown 共识。 quorum ≠ 半数:
- ODown 用
quorum判断; - Leader 选举 需同时满足半数多数派与≥ quorum。
- ODown 用
- 网络抖动/拥塞期:可能多轮选举;用超时退避降低抖动。
- 事件订阅用于观测切换进度与客户端收敛(如
+odown、switch-master)。
7️⃣ 面试高频问答(可直接背)
Q1:哨兵集群如何互相发现?如何知道从库?如何通知客户端?
A:哨兵-哨兵:主库 pub/sub 频道 sentinel:hello;哨兵-从库:向主库发 INFO 获取从库清单;哨兵-客户端:客户端订阅哨兵事件(如 switch-master)获知新主库。
Q2:ODown 判定与 Leader 选举的关系和条件?
A:先基于 quorum 达到 ODown;再进行 Leader 选举,需 半数以上 且 ≥ quorum 才能成为执行切换的 Leader。
Q3:为什么至少 3 个哨兵?
A:2 个哨兵一挂就无多数派,无法形成 ODown/Leader 共识;≥3 才具备容错与投票能力。
Q4:哨兵越多越好吗?down-after-milliseconds 调大就一定更好吗?
A:不是。
- 哨兵过多会增加网络与一致性协调开销,一般3/5 个够用。
down-after-milliseconds过大虽降误判,但会延长故障发现与切换时间;需在误判率与恢复时延间权衡,并保持各哨兵一致。
Q5:切换过程中客户端能否无感?需要做什么?
A:短暂不可用窗口难免,但可尽量无感:
- 客户端实现哨兵发现、自动重连/重试、合理超时;
- 订阅
switch-master等事件快速收敛到新主库。
8️⃣ 考前 30 秒复盘清单
sentinel:hello互发现;INFO拿从库;哨兵事件通知客户端- SDown vs ODown,
quorum与 半数多数派的区别 - Leader 选举双条件:>N/2 且 ≥ quorum
- 至少 3 个哨兵,配置(尤其
down-after-milliseconds)一致 - 客户端需具备:哨兵发现 + 重试/重连 + 超时
- 哨兵数量与
down-after-milliseconds的权衡取舍
09 | 切片集群:数据增多了,是该加内存还是加实例?
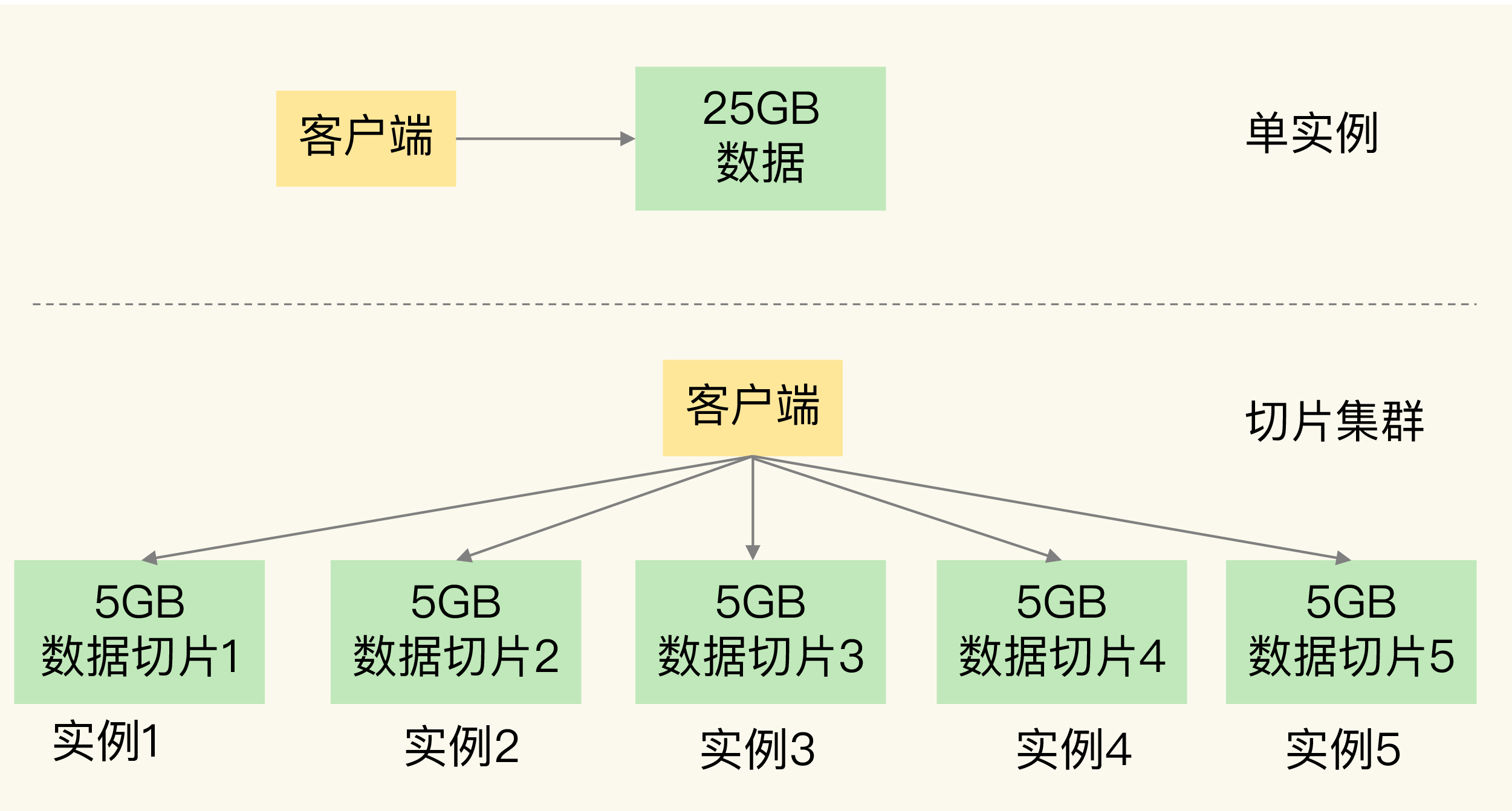
🧩 一、核心知识框架梳理
1. Redis 扩容问题背景
- 需求:存储 5000 万键值对,每个约 512B,总约 25GB 数据。
- 误区:以为 32GB 内存足够,结果出现 Redis 响应变慢。
- 原因:Redis RDB 持久化时 fork 子进程阻塞主线程,数据量大导致 fork 耗时增加。
2. Redis 扩容的两种方式
| 扩展方式 | 含义 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 纵向扩展 (Scale Up) | 提升单实例资源(内存/CPU/磁盘) | 简单、部署方便 | 受硬件限制,fork 阻塞问题严重 | 数据量不大、无持久化需求 |
| 横向扩展 (Scale Out) | 启动多个实例组成集群 | 扩展性好,fork 压力分散 | 需要分布式管理、客户端路由复杂 | 大规模数据、高并发场景 |

3. Redis 切片集群(Sharding Cluster)
- 概念:将数据切成多片,每片由不同 Redis 实例存储。
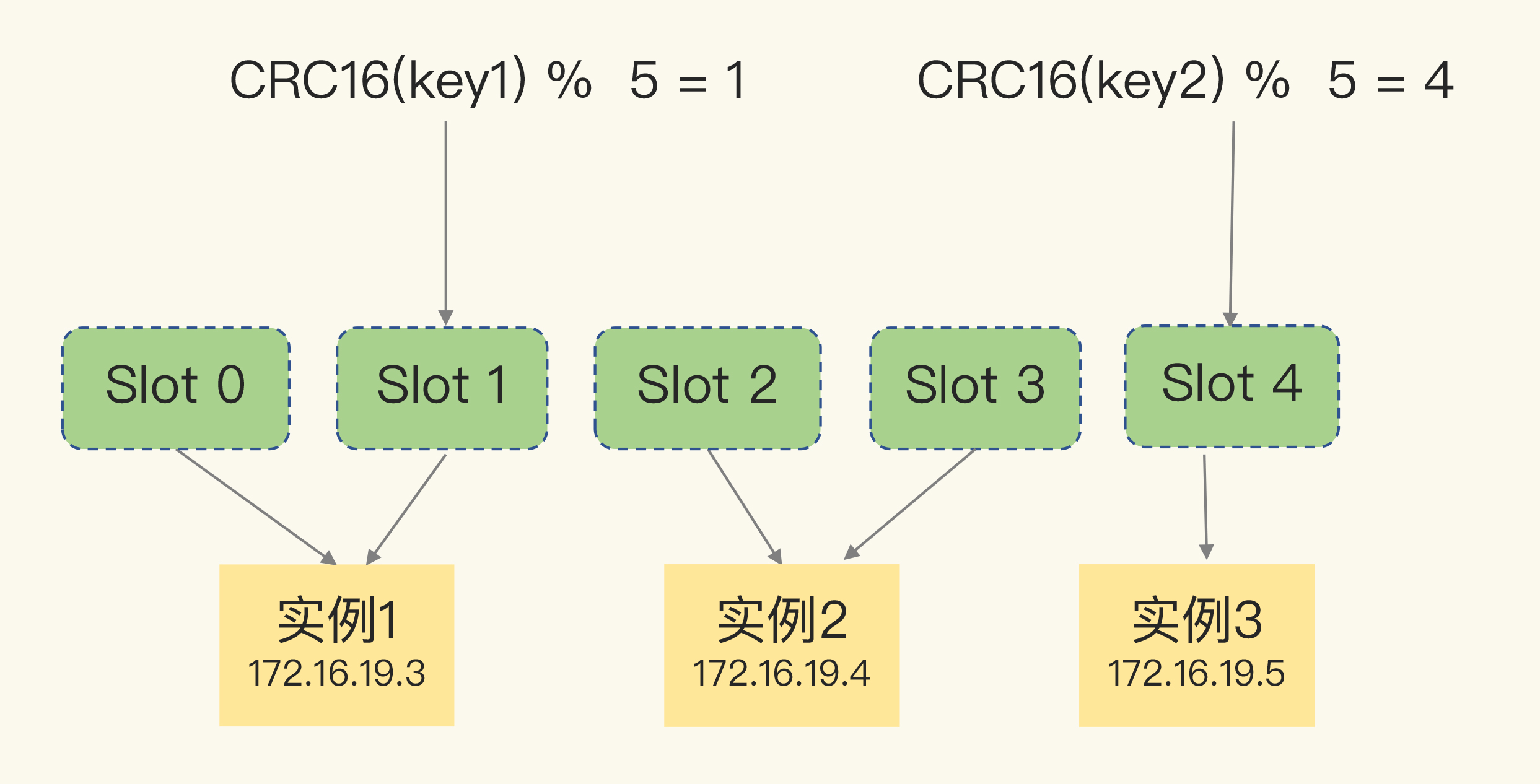
关键机制:哈希槽(Hash Slot)
- Redis Cluster 将所有 key 映射到 16384 个 Slot。
计算公式:
slot = CRC16(key) % 16384每个实例持有若干 Slot,通过命令:
cluster addslots {slot编号列表}- 可均分,也可根据实例资源手动分配。
4. 客户端如何定位数据
(1)哈希槽信息传播
- 每个实例知道自己的槽;
- 实例间传播后,全网共享槽映射;
- 客户端连接任一实例 → 获取槽分布信息 → 缓存本地。
(2)重定向机制
- 当槽迁移或集群变更后,客户端缓存可能过期。
| 命令类型 | 含义 | 客户端动作 | 是否更新本地缓存 |
|---|---|---|---|
| MOVED | 槽已迁移至其他实例 | 重新连接目标实例 | ✅ 更新缓存 |
| ASK | 槽迁移中,部分数据已转移 | 先ASKING,再执行请求 | ❌ 不更新缓存 |
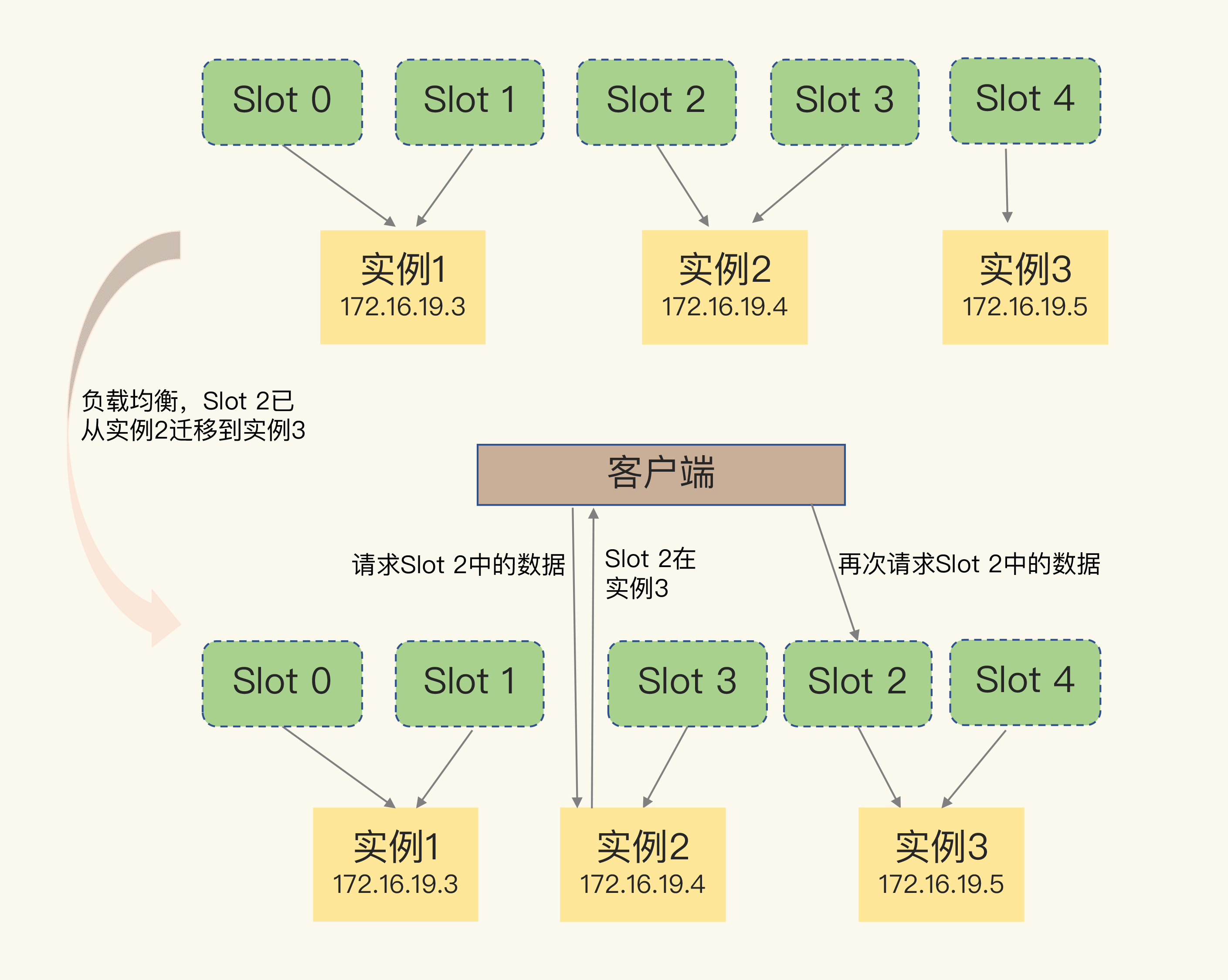
5. Redis Cluster 的设计优势
哈希槽机制比“直接建表记录 key→实例映射”更好:
- 节省内存:不需为每个 key 维护映射表;
- 计算高效:CRC16 + 取模开销小;
- 迁移简单:以槽为单位迁移,无需逐 key 记录;
- 负载均衡更自然。
💡 二、Go 后端开发面试重点与考点
✅ 高频问答题方向
| 面试问题 | 考察要点 |
|---|---|
| Redis fork 为什么导致卡顿? | Redis 单线程,fork 会复制页表(COW 机制),数据大时阻塞主线程。 |
| RDB 和 AOF 有什么区别? | RDB 快照持久化速度快但耗内存,AOF 逐步写入日志更安全。 |
| 如何解决 Redis 持久化阻塞问题? | 使用切片集群、关闭持久化、或采用混合持久化优化。 |
| Redis Cluster 的哈希槽机制有什么作用? | 分配均衡、迁移方便、快速定位数据实例。 |
| MOVED 与 ASK 的区别? | MOVED = 槽已迁移并更新缓存;ASK = 槽迁移中,不更新缓存。 |
| 纵向扩展 vs 横向扩展 区别? | 纵向是加配置;横向是加实例;横向可无限扩展。 |
🧠 延伸思考题(面试深问)
Redis Cluster 为什么不用 “key → 实例表” 的方式映射?
答:
- 维护成本高(每个 key 需存表);
- 内存占用大;
- 迁移复杂;
- 哈希槽通过计算即可快速确定,O(1) 定位,无需额外存储;
- 可自然支持负载均衡与动态扩容。
10 | 常见问题答疑
🧩 一、核心知识框架梳理
🔹问题 1:rehash 的触发时机与渐进式机制
✅ 1. rehash 触发条件
Redis 的哈希表会根据装载因子 (load factor) 决定是否 rehash。
- 装载因子 = 元素个数 / 哈希桶个数
触发条件如下:
- 装载因子 ≥ 1 且允许 rehash 时(系统未进行 RDB/AOF);
- 装载因子 ≥ 5 时,无论是否允许,都会强制 rehash(性能已明显下降)。
禁止 rehash 的情况:
- 正在生成 RDB 快照;
- 正在执行 AOF 重写。
✅ 2. 渐进式 rehash 的执行方式
Redis 为避免一次性 rehash 带来的性能抖动,采用渐进式 rehash:
- 每次执行部分 key 的迁移。
触发机制:
- 有新请求访问哈希表时执行;
- 即使无请求,也有定时任务(每 100ms 左右)自动触发;
- 每次执行不超过 1ms,防止阻塞主线程。
💬 面试延伸
Q: 为什么 Redis 要使用渐进式 rehash?
A: 避免一次性全表迁移造成主线程长时间阻塞;通过小步执行平滑迁移,保障低延迟性能。
🔹问题 2:主线程、子进程、后台线程的区别
| 类型 | 创建方式 | 作用 | 特点 |
|---|---|---|---|
| 主线程(主进程) | Redis 启动时创建 | 处理客户端请求、执行命令 | 单线程、事件驱动 |
| 子进程 | fork() 创建 | 处理持久化任务:bgsave、bgrewriteaof、无盘复制 | 独立内存空间,复制主线程页表 |
| 后台线程 | pthread_create() 创建 | 异步任务:异步删除、lazyfree、I/O flush 等 | 共享内存,非核心逻辑 |
📘 从 Redis 4.0 开始引入后台线程机制,主要用于执行耗时操作,减少主线程阻塞。
💬 面试延伸
Q: Redis 是单线程的吗?
A: 主线程是单线程的,但从 Redis 4.0 开始引入后台线程执行异步任务。Redis 整体是主线程 + 多后台线程模型。
🔹问题 3:写时复制(Copy-On-Write, COW)底层机制
✅ 1. 背景
当执行 bgsave 时,Redis 主线程会通过 fork() 创建子进程。此时:
- 子进程复制主线程的页表(不是数据本身)。
- 页表指向相同的物理内存页。
✅ 2. 写时复制的工作机制
- 子进程在读数据生成 RDB;
- 主线程继续处理写操作;
当主线程修改数据时:
- 检测到页为共享页;
- 分配一个新物理页;
- 将修改后的数据写入新页;
- 更新自己的页表;
- 子进程仍指向旧页。
👉 优点:避免数据整体复制,节省内存;
👉 缺点:fork 时复制页表仍会消耗内存,写入频繁时会导致内存膨胀。
💬 面试延伸
Q: Redis 的持久化过程中为什么可能引发内存峰值?
A: 因为 COW 机制下,大量写入会复制页,导致额外内存占用。
🔹问题 4:replication buffer vs repl_backlog_buffer 区别
| 对比项 | replication buffer | repl_backlog_buffer |
|---|---|---|
| 作用 | 全量复制时的临时缓冲区 | 增量复制(部分同步)专用缓冲区 |
| 创建时机 | 主库与从库建立连接后 | Redis 启动时创建 |
| 作用范围 | 每个从库独立持有 | 所有从库共享 |
| 控制方式 | client_buffer 参数控制 | repl-backlog-size 参数控制 |
| 主要功能 | 缓存全量传输数据(RDB + 命令) | 保存主库写命令,支持断线后部分同步 |
| 释放机制 | 从库同步完成后释放 | 一直存在,循环写入(环形缓冲区) |
💬 面试延伸
Q: 为什么 Redis 需要两个 buffer?
A: 因为全量同步与增量同步需求不同。前者是临时数据传输缓存;后者是持续记录主库写命令用于断点续传。
💡 二、Go 后端开发面试高频考点汇总
| 知识点 | 面试角度 | 典型提问 |
|---|---|---|
| rehash 机制 | Redis 字典结构优化 | Redis 为什么要分阶段 rehash?触发条件是什么? |
| 单线程模型 | Redis 架构理解 | Redis 真的是单线程吗? |
| COW 写时复制 | 持久化性能优化 | Redis 的 COW 是如何工作的?为什么会占用更多内存? |
| 复制机制 buffer 区别 | 主从同步机制 | replication buffer 和 repl_backlog_buffer 有何区别? |
| 后台线程 | 性能与异步机制 | Redis 哪些操作是后台线程完成的? |
| fork 性能瓶颈 | 实际性能调优 | Redis 为什么 fork 会导致延迟?如何优化? |
🚀 三、实战与备考建议
✅ 1. 实践建议
动手实验:
- 使用
redis-cli info memory观察 RDB 期间内存变化; - 手动触发
bgsave,同时进行写入,观察写时复制效果。
- 使用
代码层面:
- 在 Go 中使用
go-redis模拟主从复制与 failover。 - 利用
CLIENT LIST查看每个从库对应的 replication buffer。
- 在 Go 中使用
✅ 2. 面试技巧
回答机制类问题时,多用 “因为 + 机制 + 影响 + 解决方式” 的结构。
示例:Redis 使用写时复制是为了让持久化子进程独立写 RDB,但这会导致写操作时内存激增,可通过控制写入速率或使用更高版本 Redis 的 lazy-free 来缓解。
✅ 3. 推荐复习路径
- Redis 内存模型与数据结构(hash、list、zset 等底层实现)
- Redis 持久化(RDB / AOF / 混合持久化)
- Redis 主从复制机制与高可用架构(哨兵、Cluster)
- 性能调优:fork、rehash、COW、pipeline、IO 多线程
11 | “万金油”的String,为什么不好用了?
一、文章在讲什么?
文章讨论一个真实问题:
保存大量“图片ID → 图片存储对象ID”的简单键值对,为什么用 Redis String 会占用超大内存?有没有更节省内存的方案?
他们存了 1 亿条记录,每条记录只有 16 字节有效数据,却占了 64 字节内存。
于是想办法:把 String 换成 Hash,并利用 Hash 的底层结构“压缩列表(ziplist)”来节省内存。
最终效果:
- String 每条 64 字节 → 总共约 6.4GB
- Hash(ziplist)每条仅 16 字节 → 降到原来的 1/4
二、为什么 String 内存占这么多?
原始数据:
- 图片ID:10位数字 → 用 long(8 字节)
- 图片对象ID:10位数字 → long(8 字节)
理论只需要 16 字节。
但 Redis String 不是只存数据,它要存一堆“元数据”。包括:
1. RedisObject(16 字节)
所有 Redis 数据类型都有的结构,包含:
- 8 字节元信息
- 8 字节指针(int 编码时直接存 long)
→ 共 16 字节
2. 字符串使用 SDS(Simple Dynamic String)
SDS 有额外字段:
- len(4 字节)
- alloc(4 字节)
- buf[](最后还要加一个
\0)
即便内容只有几字节,也会额外占用这些。
3. dictEntry(实际 32 字节)
Redis 的全局哈希表存储所有 key-value
dictEntry 内含三个指针:
- key 指针
- value 指针
- 下一个 entry 指针
理论上是 24 字节,但 jemalloc 会按 2 的幂次分配 → 实际为 32 字节。
最终加总:
| 构成 | 大小 |
|---|---|
| RedisObject | 16 |
| dictEntry | 32 |
| SDS 结构及数据 | 16 左右(即使 int 编码有优化,但整体下来合计 64) |
所以:
一条看似只需要 16 字节的数据,String 却要用到 64 字节。
三、如何节省内存?用 Hash(内部采用 ziplist)
Redis Hash 有两种底层实现:
- ziplist(压缩列表) → 非常省内存
- hashtable → 内存较大,不想用它
只要满足条件,就用 ziplist:
- 元素个数小于
hash-max-ziplist-entries - 单个元素长度小于
hash-max-ziplist-value
ziplist 每个 entry 只需要(大概):
- prev_len(通常 1 字节)
- encoding(1 字节)
- len(4 字节)
- content(实际的数据)
文中例子:保存一个 8 字节整数
→ entry 大约占 14 字节(算上内存分配约 16 字节)
这就是为什么每条记录只需要 16 字节。
四、如何用 Hash 保存“单值键值对”?需要二级编码
问题:Hash 是“一个 key 对应多个 field-value”,
但我们需要的是“单值”。
怎么办?
作者用了 二级编码技巧:
假设原始数据:
photo_id = 1101000060
obj_id = 3302000080把 photo_id 拆成:
- 前7位:作为 Redis 的 key
→ 1101000 - 后3位:作为 Hash 的 field
→ 060 - value = obj_id
→ 3302000080
Redis 命令类似:
HSET 1101000 060 3302000080这样 Hash 内一个 key(如 1101000)下有 1000 个 field(000~999),
满足 ziplist 的阈值,保持 Hash 的底层结构为 ziplist,非常节省内存。
五、为什么必须用“前7位 + 后3位”?
核心原因:
保证每个 Hash 元素个数 不超过
1000- 尽量让 Hash 用 ziplist
- ziplist 对内存友好,不用 dictEntry,不用指针
每个 field 和 value 都很短
- 不会超过
hash-max-ziplist-value
- 不会超过
否则 Hash 会退化成 hashtable → 内存又变大。
六、最终效果
用 String:一条 64 字节
用 Hash(ziplist):一条 16 字节
节省了 75% 内存。
七、最后的问题:除了 String、Hash,还有别的类型可以用吗?
文章最后问你:
除了 String 和 Hash,你觉得还有适用的类型吗?
你可以这样理解:
- List、Set、Zset底层也能用 ziplist
- 但它们的数据模型不是“key → 单值”
- 不太适用于“一对一映射”
真正能直接用于这个场景的除了 Hash(ziplist)和 String,
还可以考虑的是 Redis Module:比如 Redis 5 之后的 stream 或者自定义 module 类型,但不是天然适合一对一映射。
所以正常回答是:
👉 Hash 最合适,其次可以考虑自定义 Module 类型;其他内置类型不适合单值映射。
12 | 有一亿个keys要统计,应该用哪种集合?
这篇文章就是教你:遇到“一个 key 对一堆值”并且要做统计时,应该选哪种 Redis 集合类型,以及它们各自适合哪种统计模式。
核心只有 4 种统计模式:
👉 聚合统计、排序统计、二值状态统计、基数统计。
下面我给你「拆小块 + 场景联想 + 记忆小口诀」,帮你看懂 + 学会 + 记住。
一、大局观:4 种统计模式 + 6 个数据结构
先别急着看细节,先把“地图”记住:
4 种统计模式
- 聚合统计:交、并、差 —— 集合之间的“比较”
- 排序统计:要按顺序的列表、排行榜、最新评论
- 二值状态统计:只有 0/1 的状态(签过到/没签)
- 基数统计:只关心“有多少不同的人”,去重计数(UV)
6 个主要数据结构
- Set
- Sorted Set
- List
- Hash
- Bitmap
- HyperLogLog
先记一条总口诀:
**交并差找 Set,
排序首选 ZSet,
0/1 用 Bitmap,
去重估数 HLL。**
有了这张“地图”,后面就是往每一块里填细节。
二、模式 1:聚合统计(交集 / 并集 / 差集)
关键词:新增用户、留存用户、交并差、Set
1. 场景
每天登录的用户集合:
user:id:20200803:8月3日登录过的用户ID(Set)user:id:20200804:8月4日登录过的用户ID(Set)
累计登录用户集合:
user:id:历史上所有登录过的用户(Set)
要统计:
- 每天新增用户:今天登录,但历史上没出现过
- 第二天留存用户:昨天登录,今天也登录
2. 用到的 Redis 命令和思路
累计用户 Set:保存所有登录过的用户
SUNIONSTORE user:id user:id user:id:20200803把“原来的累计用户集合”和“今天的集合”做并集,结果再存回
user:id。今天的新增用户(差集)
例:统计 2020-08-04 的新增SDIFFSTORE user:new user:id:20200804 user:id把
user:id:20200804中有,但user:id中没有的用户取出来 → 新增。第二天留存用户(交集)
SINTERSTORE user:id:rem user:id:20200803 user:id:20200804同时出现在 8月3日 和 8月4日 的用户 → 留存。
3. 为什么用 Set?
Set 天然是“无序不重复集合”,支持:
- 交集
SINTER - 并集
SUNION - 差集
SDIFF
- 交集
- 正好符合“多个集合做交并差”的聚合统计需求。
4. 风险和优化
- 大集合做交并差运算,会很耗时、阻塞 Redis。
优化建议:
- 在 从库 上做这些运算;
- 或者把各集合拉回客户端,在业务层做统计。
三、模式 2:排序统计(最新评论/排行榜)
关键词:列表分页、最新评论、位置变化、Sorted Set
场景:电商商品的最新评论列表
需求:
- 看到最新的评论
通常要分页,比如:
- 第 1 页:最新 10 条
- 第 2 页:再往前 10 条
我们有两个候选:
- List
- Sorted Set(有序集合)
1. 为啥 List 不太行?
假设评论 List 为:{A, B, C, D, E, F} (A 最新、F 最旧)
- 第 1 页:
LRANGE product1 0 2→ A、B、C - 第 2 页:
LRANGE product1 3 5→ D、E、F
此时又来了一条新评论 G,用 LPUSH 插入:
- List 变成
{G, A, B, C, D, E, F}
再去拿第 2 页:LRANGE product1 3 5 → C、D、E
问题:C 重复出现了!
因为 List 是按位置排序的,新元素插入头部之后,所有元素整体往后移动,分页就乱了。
2. Sorted Set 怎么解决?
Sorted Set 里每个元素有一个score(权重),比如用“时间戳”做 score:
- 时间越新,score 越大
- 插入评论时,附上时间作为 score
然后用:
ZRANGEBYSCORE comments N-9 N按 score 范围获取最新 10 条。
即使不断有新评论插入,只要 score 正确,取数据就是稳定的。
记忆点:
- 排序 + 分页 + 不想被插入新数据影响 → Sorted Set。
- List 只适合简单队列/栈,复杂分页排序不靠谱。
四、模式 3:二值状态统计(0/1:签到)
关键词:签到、0/1 状态、超省内存、Bitmap
场景:签到打卡
- 一天的状态:只需“签了(1)”或“没签(0)”
- 一个月:31天 → 31 个 bit
- 一年:365 个 bit
完全没必要用 Set、ZSet 这种大结构,直接用 Bitmap。
1. Bitmap 是什么?
- 本质:底层是 String 的 bit 数组
- 用
SETBIT / GETBIT操作某个 bit - 用
BITCOUNT统计有多少个 1
2. 日常操作示例
记录用户 3000 在 2020年8月 的签到
约定:offset 从 0 开始,0 表示 8月1日
所以 8月3日 → offset=2
标记 8月3日已签到:
SETBIT uid:sign:3000:202008 2 1查询 8月3日是否签到:
GETBIT uid:sign:3000:202008 2统计 8 月份总签到天数:
BITCOUNT uid:sign:3000:202008
3. 连续 10 天签到人数怎么统计?
思路:
- 每天一个 Bitmap:
sign:20200801...sign:20200810 - 每个 Bitmap 有 N 个 bit,对应 N 个用户
- 把这 10 天的 Bitmap 做按位 AND(“与”):
BITOP AND sign:202008_01_10 sign:20200801 sign:20200802 ... sign:20200810
BITCOUNT sign:202008_01_10- 按位“与”的结果:只有 10 天都为 1 的用户对应的 bit 还是 1
BITCOUNT就是“连续签到 10 天”的人数
记忆点:
- 只有 0/1 状态 + 超大量用户 → Bitmap
- “按位”是否存在、是否签到等 → Bitmap + BITOP
五、模式 4:基数统计(去重计数:UV)
关键词:去重人数、Set 很准但耗内存、HyperLogLog 很省内存但有误差
场景:统计网页的 UV
- UV:Unique Visitor → 同一个用户访问多次,只算一次
- 用户可能几千万,页面可能几万个,用 Set / Hash 都很浪费内存
1. 直接用 Set 的做法
SADD page1:uv user1
SCARD page1:uv # 得到 UV 数问题:
- 每个访问用户 ID 都要存下
- 页面多、用户多 → 内存爆炸
2. 用 Hash 的做法(思路类似)
HSET page1:uv user1 1
HLEN page1:uv还是一样:精确,但很耗内存。
3. 用 HyperLogLog:超省内存的“近似去重计数”
特点:
- 一个 HyperLogLog 固定只占 ~12KB 内存
- 即使统计接近
2^64个不同元素,内存还是大概 12KB - 但统计结果是近似值,误差约 0.81%
使用:
PFADD page1:uv user1 user2 user3
PFCOUNT page1:uv # 近似 UV 数量- 如果你能接受 100万 实际是 101万、99万这种级别的误差 → 用它
- 如果你要绝对精准 → 还是 Set / Hash
记忆点:
需要“去重计数”
- 精确 + 数量不夸张 → Set / Hash
- 海量数据 + 内存敏感 + 可接受少量误差 → HyperLogLog
六、一起捋一遍:场景 → 选择什么?
我帮你把文章的 4 个场景和数据结构一一对上,你只要记这个表就够用了:
| 场景 | 需求类型 | 推荐结构 | 原因 |
|---|---|---|---|
| 每日新增用户 & 留存用户 | 交、并、差 | Set | 有交集/并集/差集操作 |
| 商品最新评论列表 | 排序 + 分页 | Sorted Set | 通过 score 排序,不怕新数据插入打乱位置 |
| 连续签到、签到统计 | 0/1 状态 | Bitmap | 1 个 bit 就能表示一个状态,极省内存 |
| 网页 UV 统计 | 去重计数 | HyperLogLog | 固定内存、适合超大规模近似统计 |
再把那句口诀看一眼:
**交并差找 Set,
排序首选 ZSet,
0/1 用 Bitmap,
去重估数 HLL。**
七、怎么更好地“记住”这篇文章?
给你一个学习/记忆小策略,你可以照着做一遍(不用特别正式,自己在纸上写写就行):
- 画一个 2×3 小表格
写上:Set / ZSet / List / Hash / Bitmap / HLL 各适合做什么。 每种统计模式,自己找一个额外例子:
- 聚合统计:比如“多渠道用户去重”(App 用户集合 ∩ Web 用户集合)
- 排序统计:比如“积分排行榜”
- 二值状态统计:比如“今天是否登录”
- 基数统计:比如“某个活动独立参与用户数”
- 用 Redis 命令简单写两三行伪代码
不一定真的去运行,但把命令写出来能加深记忆。
八、文章最后的“每课一问”怎么答?
题目:你还遇到过其他的统计场景吗?用的是怎样的集合类型呢?
你可以这样回答(示范版,可以改成你的场景):
统计接口的 QPS(每秒请求数)
- 需求:每秒请求量统计
- 方案:用 String +
INCR记录每秒的计数,而不是用集合类型
活动积分排行榜
- 需求:按积分排序、随时看前 N 名
- 方案:用 Sorted Set,用户 ID 是成员,积分是 score
统计每天购买过商品 A 的用户数(精确)
- 需求:去重计数且要精确
- 方案:Set 或 Hash,用户 ID 作为 key
你也可以把自己真实见过的一个场景写出来,比如:
比如我在 xxx 项目里做过“xxx 的统计”,当时用的是 xxx(Set/Sorted Set/Bitmap/...),原因是 xxx。
13 | GEO是什么?还可以定义新的数据类型吗?
PS:Redis定义新的数据类型基本上不会考察,所以此处不再概括。
⭐ 一、为什么需要 GEO ?Redis 原生数据结构为什么不够?
GEO 用于 地理位置存储与附近搜索(LBS)场景,例如:
- 打车软件查“附近的车”
- 外卖软件查“附近的骑手”
- 地图应用查“附近的餐厅”
这些场景有几个共同特点:
① 每个对象由一个唯一 ID(如车辆 ID)表示
例如:车辆 33
② 每个对象对应一个“二元值”(经纬度)
如(经度 116.034579,纬度 39.030452)
③ 需要两个能力:
- 根据 ID 查其位置 → 类似 Hash 的能力
- 根据一个坐标查附近的点 → 范围查询能力(需要“有序”)
❌ Hash 的问题:无序,因此不能做范围查询
虽然 Hash 可以保存 ID → 经纬度,但它是 无序结构,不能以“距离中心点”的范围来查。
❌ Sorted Set 的问题:score 只能是一个数
Sorted Set 的 score 是 float,而经纬度是两个维度(lon, lat),无法直接保存。
✔ GEO 的解决方案:
用 GeoHash 将 (经度, 纬度) 二维空间编码成一个一维数字 → 作为 score
将 ID 存为 Sorted Set 的成员
用 score 范围查询实现“附近搜索”
这就是 GEO 的本质。
⭐ 二、GEO 的底层结构:Sorted Set + GeoHash
GEO 并没有发明新数据结构
而是将两者组合:
| Redis 组件 | 在 GEO 中的作用 |
|---|---|
| Sorted Set | 负责排序与范围查询 |
| GeoHash 编码 | 将经纬度变成可比较的数字 |
Sorted Set 的:
- member = 用户/车辆 ID
- score = 经纬度经过 GeoHash 编码后的数值
因此:
附近的地理点 → score 接近
→ Sorted Set 的范围查询刚好很好用
三、GeoHash:如何把一个点变成一个数字?
这是 GEO 的核心。
GeoHash 的基本思想:
对经度和纬度不断二分区间,记录每次落在左区还是右区,生成 01 编码,再将两者交错组合。
🔶 步骤 1:经度编码(范围 [-180, 180])
例如:经度 = 116.37
编码过程示例(用 5 位编码):
| 分区次数 | 当前区间 | 二分后区间 | 位置落点 | 编码位 |
|---|---|---|---|---|
| 1 | [-180, 180] | [-180,0), [0,180] | 116.37 在右区 | 1 |
| 2 | [0,180] | [0,90), [90,180] | 在右区 | 1 |
| 3 | [90,180] | [90,135), [135,180] | 在左区 | 0 |
| 4 | [90,135] | [90,112.5), [112.5, 135] | 在右区 | 1 |
| 5 | [112.5,135] | [112.5,123.75), [123.75,135] | 在左区 | 0 |
最终经度编码:11010
🔶 步骤 2:纬度编码(范围 [-90, 90])
例如:纬度 = 39.86
类似上面的流程,假设编码得到:10111
🔶 步骤 3:合并编码(经度和纬度“交叉位”)
合并规则:
- 偶数位放经度
- 奇数位放纬度
经度:1 1 0 1 0
纬度:1 0 1 1 1
组合:
索引0 经度1
索引1 纬度1
索引2 经度1
索引3 纬度0
索引4 经度0
索引5 纬度1
索引6 经度1
索引7 纬度1
索引8 经度0
索引9 纬度1最终得到:1110011101
这就是转换成 Sorted Set 的 score 值。
⭐ 四、把地球划成格子:GeoHash 的空间意义
如果将 2 次二分(经度2位 + 纬度2位)可得到 4×4 = 16 个大格。
编码越多位:
- 格子越小(范围越精准)
- score 越接近表示越接近的格子
例如:
| 编码 | 所属格子描述 |
|---|---|
| 00 | 西半球、南半球 |
| 01 | 西半球、北半球 |
| 10 | 东半球、南半球 |
| 11 | 东半球、北半球 |
进一步细分后(更多位)得到更多更小的格子。
这样:
“附近” → “相邻格子” → “score 值范围接近”
Sorted Set 范围查询即可实现附近搜索。
⭐ 五、真实的“附近搜索”需要查询多个格子
GeoHash 有一个缺陷:
数学上接近的编码不一定空间上相邻
因为空间是二维,GeoHash 折线扫描会有跨区问题
例如编码:
0111 和 1000虽然数值很接近,但实际上处于完全不同的方格。
因此:
真正的附近搜索需要多区块查询(通常是 5 至 9 个区域)
即:
- 当前格子
- 上下左右 4 个格子
- 再加上对角 4 个格子(可选)
Redis 内部的 GEORADIUS 已经做了“多格子搜索”,我们不用手工计算。
⭐ 六、GEO 的核心命令(业务最常用)
① GEOADD:添加地理位置
GEOADD cars:locations 116.034579 39.030452 33意思:车辆 33 当前在给定坐标。
Redis 内部做了:
- (lon, lat) → GeoHash → 数值 score
- 加入 Sorted Set
② GEORADIUS:查指定坐标附近对象
GEORADIUS cars:locations 116.054579 39.030452 5 km ASC COUNT 10含义:
- 搜索距离该点 5km 内的对象
- 按距离升序排序
- 最多返回 10 条
这些逻辑内部都基于 Sorted Set 的范围查 + 实际距离再过滤。
⭐ 七、GEO 适合/不适合的场景
✔ 适合
- 查“附近的用户/车/店”
- 经纬度不需要特别精确(几十米-几百米)
- 数据量大、速度要求极快的系统
❌ 不适合
- 精度要求极高(例如 10 米以内)
- 需要复杂地理查询(多边形、行政区范围)
→ 推荐使用 GIS 引擎:PostGIS / Elastic Search Geo
⭐ 八、总结(GEO 部分完整知识体系)
Redis GEO = Sorted Set + GeoHash
GeoHash 解决二维 → 一维映射问题
Sorted Set 解决范围查询问题
GEORADIUS 自动完成多格子查询,实现附近搜索
14 | 如何在Redis中保存时间序列数据?
🎯 面试场景:时间序列数据存储 (Time Series Data)
核心问题:如何设计一个系统来存储海量的 IoT 设备状态(温度、压力)或互联网用户行为(点击流)?
1. 数据特征(面试必答点)
在回答方案前,先向面试官阐述你对这种数据的理解,这体现了你的专业度:
写操作:
- 高并发写入:数据量大,写入频繁。
- 只追加(Append Only):一旦记录,几乎不修改(Immutable)。
读操作:
- 点查询:查某个具体时间点的值。
- 范围查询:查某段时间内的所有记录。
- 聚合计算:查某段时间的均值、最大值(这是最消耗性能的)。
🚀 方案一:基于 Redis 原生数据结构 (Hash + Sorted Set)
这是面试中最稳妥的方案,因为不需要引入外部模块,依赖低。
架构设计
这也是一种“空间换时间/功能”的策略,即一份数据存两份:
Hash 结构:
Key: 设备IDField: 时间戳Value: 数据值- 目的:解决点查询问题。
HGET时间复杂度 O(1),极快。 - 缺陷:Hash 无序,无法高效做范围查询。
Sorted Set (ZSet) 结构:
Key: 设备IDScore: 时间戳Member: 数据值 (或时间戳引用)- 目的:解决范围查询问题。利用
ZRANGEBYSCORE根据时间戳范围拉取数据。
关键考点 (面试高频)
原子性问题(Consistency):
- 问:你怎么保证写 Hash 和写 ZSet 是一致的?如果写了 Hash 没写 ZSet 怎么办?
- 答:使用 Redis 的 Pipeline 配合
MULTI和EXEC命令(简单的事务机制)。在 Go 中使用go-redis的TxPipeline来保证这两个写入命令要么都成功,要么都不执行。
性能瓶颈(Performance):
- 问:如果我要算过去 1 小时的平均温度,这套方案有什么问题?
- 答:网络带宽瓶颈。ZSet 只能把原始数据取回到 Go 服务端(Client 端),然后在 Go 代码里做遍历计算。如果数据量很大(比如 100 万条),会在 Redis 和 Go 服务之间产生巨大的网络流量,可能打爆网卡。
🛠 方案二:基于 RedisTimeSeries 模块
这是进阶方案,适用于对聚合计算要求极高的场景。
架构设计
使用 Redis 的扩展模块 RedisTimeSeries。它专门为时序数据优化。
核心优势 (面试亮点)
服务端聚合 (Server-side Aggregation):
- 这是它最大的杀手锏。
- 对比:方案一需要把 1 万条数据拉到 Go 服务里算平均值;方案二直接告诉 Redis “给我算好过去 1 小时的平均值再传回来”。
- 结果:网络传输数据量由 1 万条变成了 1 条,极大地节省了带宽和 Go 服务的 CPU。
自动过期 (Retention):
- 创建时指定
RETENTION,过期数据自动清理,省去了手动写脚本清理过期数据的麻烦。
- 创建时指定
缺点与风险
- 运维成本:需要加载第三方模块(
redistimeseries.so),很多公司的云 Redis 服务可能不支持加载自定义模块。 - 查询限制:
TS.GET只能查最新的,无法像 Hash 那样查任意历史时间点的单条记录(虽然可以通过 Range 查,但效率不同)。
⚖️ 总结:面试官问你“怎么选”?
你可以给出以下决策矩阵,展示你的架构权衡能力:
| 考量维度 | 方案 A (Hash + ZSet) | 方案 B (RedisTimeSeries) | 建议选择 |
|---|---|---|---|
| 数据规模 | 中小规模 | 海量数据 | |
| 聚合需求 | 很少聚合,主要是查原始记录 | 频繁聚合 (均值/求和/监控报警) | 聚合多选 B |
| 网络带宽 | 带宽充足 | 带宽紧张 | |
| 运维环境 | 纯原生 Redis,无法安装插件 | 自建 Redis 或支持插件的云服务 | 受限环境选 A |
| 开发复杂度 | 较高 (需维护双写原子性) | 低 (内置命令) |
💡 给 Go 开发者的代码实现 Tips (加分项)
在面试中提到具体的 Go 实现细节会很加分:
- 使用 Pipeline:强调在 Go 中处理方案一的双写时,一定要用
client.Pipeline()或client.TxPipeline(),这能减少 RTT(往返时间)。 - 序列化:ZSet 的 Member 如果是复杂结构(比如既有温度又有湿度),在 Go 中通常会序列化成 JSON 字符串存进去,或者 Member 只存时间戳,查的时候再回 Hash 查详情(以时间换空间)。
一句话总结给面试官:
“如果业务主要是查最新的状态或者简单的范围记录,为了系统稳定性,我会用 Hash+ZSet 配合 Pipeline 保证原子性;但如果是做监控大盘,需要高频地做降采样(Downsampling)和聚合计算,为了避免网络风暴,我会强烈建议引入 RedisTimeSeries 模块。”
15 消息队列的考验:Redis有哪些解决方案?
这是一份基于你提供的文章,专门针对 Go 后端开发面试 场景整理的总结与划重点。
在 Go 面试中,面试官通常考察你对并发模型(Goroutine)与中间件(Redis)结合使用的深度。这篇文章的核心在于:如何利用 Redis 的特性去模拟这一专业的中间件行为。
🚀 Redis 做消息队列(Go 面试突击版)
1. 核心背景:为什么考虑 Redis 做 MQ?
- 面试场景:当系统不需要 Kafka/RabbitMQ 这种“重型”组件(部署复杂、运维成本高),且消息量级适中时,Redis 是轻量级的替代方案。
- Go 开发相关性:Go 的高并发特性(Goroutine)非常适合配合 Redis 的阻塞读取命令(如
BRPOP),实现高效的消息消费。
2. 消息队列的三大核心需求 (面试必考点)
面试官问“Redis 能做 MQ 吗?”其实是在问“Redis 能解决以下三个问题吗?”:
- 消息保序 (Ordering):消费者必须按发送顺序处理(如:先扣库存 5,再扣库存 3,顺序反了结果就错了)。
- 处理重复消息 (Idempotency):网络抖动可能导致消息重传,消费者必须能处理重复消息(幂等性)。
- 消息可靠性 (Reliability):消费者宕机后,未处理完的消息不能丢失。
3. 方案一:基于 List 的实现 (老派方案)
这是 Redis 最基础的队列实现方式,适合简单的任务队列。
基本原理:
- FIFO 模型:生产者
LPUSH,消费者RPOP。 - 保序性:List 本身就是有序的,天然满足。
- FIFO 模型:生产者
痛点与解决方案 (重点):
CPU 空转问题:普通的
RPOP需要轮询(Polling),浪费 CPU。- Go 优化:使用
BRPOP(Blocking Pop)。当队列为空时阻塞连接,有数据时立即返回。这在 Go 中通常对应一个运行在 Goroutine 中的无限循环,阻塞等待不占用 CPU 资源。
- Go 优化:使用
重复消息处理:List 不自带唯一 ID。
- 解决方案:生产者必须在 Payload 中塞入全局唯一 ID,消费者自行维护“已处理 ID 集合”来实现幂等。
可靠性问题 (消息丢失):
RPOP读出来后,Redis 就删了。如果消费者拿到消息还没处理完就 Panic 了,消息就丢了。- 解决方案:使用
BRPOPLPUSH。读的同时,把消息塞入另一个“备份 List”。如果处理失败,备份 List 里还有。
- 解决方案:使用
List 的致命缺陷:
- 不支持消费组 (Consumer Group):无法简单地让多个消费者共同分担读取一个队列(且不重复消费)。虽然可以多开 Goroutine 抢
BRPOP,但无法像 Kafka 那样优雅地管理 Offset。
- 不支持消费组 (Consumer Group):无法简单地让多个消费者共同分担读取一个队列(且不重复消费)。虽然可以多开 Goroutine 抢
4. 方案二:基于 Streams 的实现 (Redis 5.0+ 推荐方案)
这是 Redis 为了解决 List 做 MQ 的缺陷,专门推出的数据结构,面试中加分项。
核心命令与特性:
XADD(生产):插入消息,自动生成全局唯一 ID(时间戳+序号),解决了 List 没有 ID 的问题。XREAD(消费):支持阻塞读取 (BLOCK),类似BRPOP。XGROUP(消费组):这是重点。支持类似 Kafka 的消费组模式。- 可以让一组消费者(Consumer Group)共同消费一个 Stream。
- 保证同组内一条消息只被一个消费者读取(负载均衡)。
XPENDING&XACK(可靠性):- Redis 内部维护一个 PENDING List(已读取但未确认)。
- 消费者处理完必须发送
XACK。 - 如果消费者宕机重启,可以通过
XPENDING查出自己“挂起”的消息继续处理,完美解决可靠性问题。
5. 总结与选型对比 (面试收尾)
List vs Streams 对比表:

面试官问:到底选 Redis 还是 Kafka?
选 Redis (List/Streams):
- 业务刚起步,为了架构简单,不想引入 ZooKeeper 等外部依赖。
- 消息积压量不大(因为 Redis 是基于内存的,积压太大会炸内存)。
- 对数据零丢失要求不是极端严格(Redis AOF/RDB 持久化有窗口期)。
选 Kafka/RabbitMQ:
- 海量数据堆积。
- 严格的事务要求。
- 极高的吞吐量需求。
💡 针对 Go 开发者的 Next Step
在实际 Go 代码(使用 go-redis/v9 库)中,基于 Streams 的消费者模型通常长这样。你可以尝试写一个小的 Demo:
- 启动一个 Goroutine 使用
XReadGroup阻塞读取消息。 - 读取到消息后,执行业务逻辑。
- 业务逻辑无误,执行
XAck。 - 另起一个 Goroutine 定期扫描
XPending,处理那些长时间未 ACK 的“死信”。
